Продолжаем серию статей о техническом аудите. Наверняка многие слышали, что дубли страниц – это плохо. Сегодня, как и обещали, подробнее разберемся в этой теме.
Что такое дубли страниц?
Страницы считаются дублями, когда они доступны по разным адресам, но при этом имеют одинаковое содержание. Поисковые роботы такие страницы признают некачественными и удаляют из выдачи ранжируя только одну из них.
Дубли страниц могут появиться по разным причинам. Например, на сайте интернет-магазина дубли могут появляться, когда страница одного товара присутствует в разных категориях сайта по разным URL. Но могут быть и другие причины, которые связаны с неправильной организацией структуры сайта, при автогенерации документов, некорректных настройках или неправильной кластеризации.
Чем так опасны дубли страниц?
В индекс попадет меньше полезных страниц.
Если в вашем проекте, предположим, несколько сотен тысяч страниц, и на сайте 30-50% это дубли, то общий объем сайта раздуется в 1,5 - 2 раза.
Поисковому роботу потребуется значительно больше ресурсов для полного переобхода ресурса. Важно, некоторые страницы робот будет довольно редко обходить, т.к. у поисковой системы на каждый сайт выделен определённый крауленговый бюджет.
Неверно распределяется внутренний ссылочный вес.
Имея ссылки на дубли документов часть внутренней ссылочной массы будет распределяться между оригиналом и копией, что уменьшит значимость основной страницы. Встречались ситуации, когда на копию было больше ссылок, чем на оригинал и выдаче появлялся дубль.
Теряется внешний ссылочный вес.
Если пользователь решит поделиться информацией со страницы дубля, то он будет ссылаться именно на нее, а значит вы потеряете полезную естественную ссылку. Если по данной ссылке будут переходы, то поведенческие факторы учтутся для страницы дубля.
Разделение поведенческих факторов на 2 документа.
Из-за наличия дубля по одному и тому же запросу может отображаться то одна, то вторая страница. Некоторые пользователи будут заходить на основную страницу, а другие перейдут на дубль. В результате вместо того, чтобы получить качественные данные по поведенческим факторам для правильного документа, в статистике отобразится часть сведений для него, а часть - для дубля. Как итог - общие поведенческие факторы для документа могут быть хуже и повлекут за собой низкое ранжирование.
Получается, дубли страниц довольно опасны с точки зрения SEO. Они критично воспринимаются поисковыми системами и могут привести к серьезным потерям в трафике.
Кроме этого, за повторяющийся контент можно получить санкции от поисковых систем. Для Гугла они будут выражаться в резком, а для Яндекса в более плавном проседании позиций.
Существует фильтр, который так и называется “Повторяющийся контент”. Применяется он из-за наличия неуникальной информации: на поддоменах , в сквозных блоках текста, отзывах, преимуществах, тарифах или портфолио, из-за неверно настроенных страниц пагинации, шаблонных текстов (например, текст политики конфиденциальности), и т.д.
Если вы хотите узнать больше об этом фильтре, напишите в комментариях, и мы с удовольствием расскажем вам о нем подробнее.
Откуда берутся дубли?
Дублями считается, как полное совпадение контента на страницах, так и частичное, когда некоторая часть контента дублируется на ряде страниц, хоть они и не являются абсолютными копиями. В целом, поисковики наиболее критично относятся к полным дублям, но не стоит забывать о том, что и частичные дубли также могут негативно сказываться на позициях.
Рассмотрим основные причины возникновения дублей:
Генерация дублей CMS:
Распространенной причиной появления дублей являются ошибки в CMS. Например, часто дубли генерирует WordPress, т.к. страница учитывается только по последней части URL:
Например:
- http://site.ru/chto-takoe-audit/
- http://site.ru/blog/chto-takoe-audit/
Страницы по разным URL могут друг друга дублировать.
Одна и та же страница расположена по адресу с «www» и без «www»:
- https://www.site.ru/blog/
- https://site.ru/blog/
Для поисковых систем подобные домены считают, как 2 разных сайта поэтому это приводит к полному дублированию всего сайта.
Дубли страниц с протоколами http и https:
- https://site.ru/blog/
- http://site.ru/blog/
Аналогично пункту 2, но в данном случае, разные протоколы по которым доступен сайт.
Страницы с прописными и строчными буквами в URL:
- http://site.ru/seo/
- http://site.ru/SEO/
Дубли страницы по адресам:
- http://site.ru/index
- http://site.ru/index/
- http://site.ru/index.php
- http://site.ru/index.php/
- http://site.ru/index.html
- http://site.ru/index.html/
Один из этих адресов может быть основным адресом страницы по умолчанию.
Пример дублей (на момент написания статьи):
- http://biggreenegg-russia.ru/vysokaya-kuhnya/kulinarnye-dostizheniya.html
- http://biggreenegg-russia.ru/vysokaya-kuhnya/kulinarnye-dostizheniya.html.html
Дубли, сгенерированные реферальной ссылкой
Обычно такие страницы содержат специальный get-параметр, который добавляется к URL. И если они, не меняя содержание, меняют сам параметр в URL, то становятся дублями. В данном случае рекомендуем настроить rel= «canonical» на страницу без параметра.
К возникновению дублей приводят и ошибки в иерархии URL.
Например, один и тот же товар может быть доступен по адресам:
- http://site.ru/catalog/dir/tovar.php
- http://site.ru/catalog/tovar.php
- http://site.ru/tovar.php
- http://site.ru/dir/tovar.php
Например, в Bitrix часто можно встретить такие дубли, когда URL товаров привязывают к разным категориям и в каждой категории товары формируются по ссылке формата: сайт+категория+товар:
- http://site.ru/categogiy-1/tovar-1
- http://site.ru/categogiy-2/tovar-1
Полные дубли легче найти и устранить, чем частичные. Чаще всего причина их появления зависит от особенностей CMS и навыков разработчика сайта.
Что касается частичных дубликатов, то их найти сложнее.
Главными причинами появления частичных дублей являются:
Страницы пагинации, фильтров, сортировок.
Например, на сайте интернет-магазина выводимый ассортимент может изменяться на страницах отдельных категорий, но при этом SEO-текст, заголовки и мета-данные – не меняются.
- http://site.ru/catalog/category/ — стартовая страница категории товаров
- http://site.ru/catalog/category/?page=2 — страница пагинации
При том, что URL изменился и робот будет индексировать его как отдельную страницу основной SEO – контент будет продублирован.
Страницы комментариев, характеристик, отзывов.
Часто встречается ситуация, когда при выборе необходимой вкладки на странице товара происходит добавление параметра в URL адрес, но сам контент фактически не меняется.
Например:
- https://www.site.ru/c/399/clothes-bluzy-rubashki/?sitelink=topmenuW&l=2
- https://www.site.ru/c/399/clothes-bluzy-rubashki/
Несмотря на то, что эти страницы имеют разный адрес, их содержимое совпадает на 100%.
Версии для скачивания и для печати.
Такие страницы полностью дублируют контент основных страниц, но при этом имеют упрощенную версию из-за отсутствия большого количества строк кода.
Например:
- http://site.ru/main/hotel/al12188 — страница отеля
- http://site.ru/main/hotel/al12188/print — черно-белая версия для печати
- http://site.ru/main/hotel/al12188/print?color=1 — цветная версия для печати.
Решением для таких дублей является настройка атрибута rel="canonical", который укажет на основной адрес.
Дубли в скрытых (всплывающих) блоках.
Часто информация дублируется в блоках, которые появляются после клика или наведения курсора на элемент, например, на кнопку.
Такими блоками могут быть: формы обратной связи, политика конфиденциальности.
Наличие не уникальных тегов Title, Description, H1.
Иногда такие страницы, тоже ПС принимают за дубли. Теги Title, Description, H1 должны содержать информацию, описывающую страницу, на которой они находятся. Так как на сайте не должно быть одинаковых страниц, то и мета-теги должны быть уникальными на каждой странице и не должны дублироваться.
К появлению дублей могут приводить и другие причины, например, человеческий фактор, т.е. банальное дублирование статей. А некоторые ошибки могут возникать и по причине отсутствия редиректа со старой страницы на новую, из-за особенностей отдельных скриптов и плагинов. С каждой такой проблемой лучше разбираться по отдельности.
Как искать дубли?
Теперь давайте рассмотрим, как можно найти внутренние дубли на сайте.
- Первый и самый простой из способов – посмотреть в Яндекс. Вебмастере или в Google Search Console.
Поиск ошибок в Яндексе:
Переходим в раздел: “Страницы в поиске”:
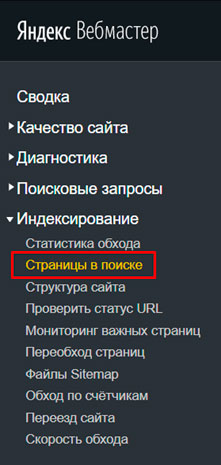
Далее выбираем вкладку “Исключенные страницы”
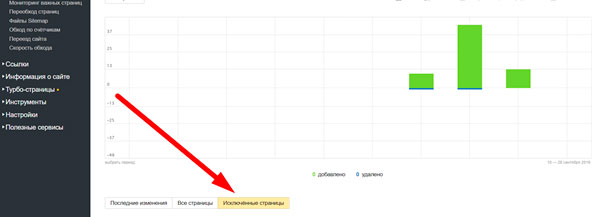
В столбце Статус указываем фильтрацию по “Дубль”
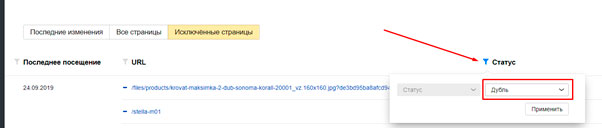
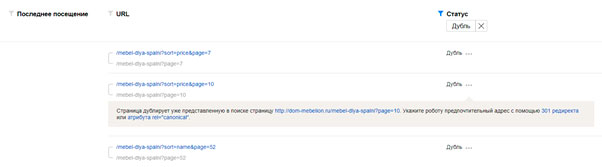
В результате увидим все страницы, признанные дублями.
Поиск дублей в Google:
Переходим в раздел “Покрытие”
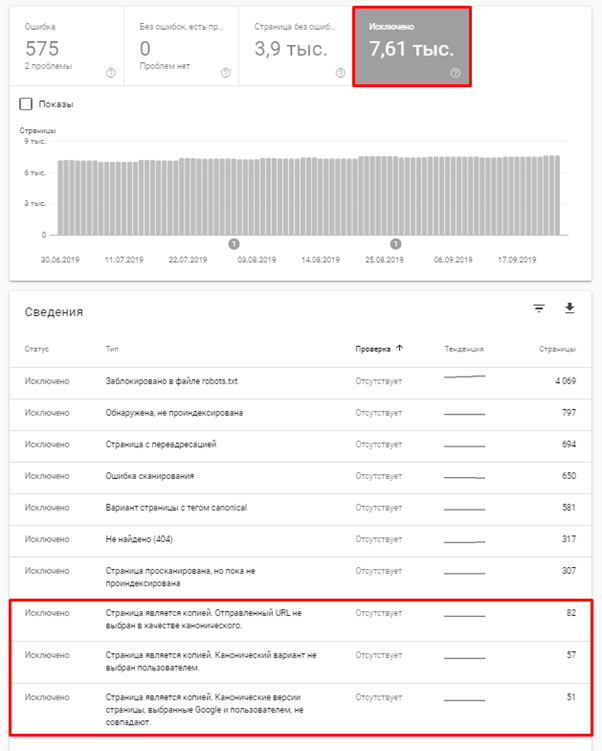
Смотрим вкладку “Исключено”. Здесь может быть 3 варианта ошибок с дублями (представлено на скрине)
Проверить страницы на совпадающие заголовки можно даже тогда, когда у вас нет доступа к панели. Для этого нужно ввести в поисковую строку соответствующий запрос.
Для Яндекса:
site: vashdomen.ru title:”заголовок”
Конечно, здесь нужно указать свой домен и тег Title, дубль которого вы ищете. Обратите внимание, что здесь необходимо добавлять тег Title полностью, а не только некоторые слова из него.
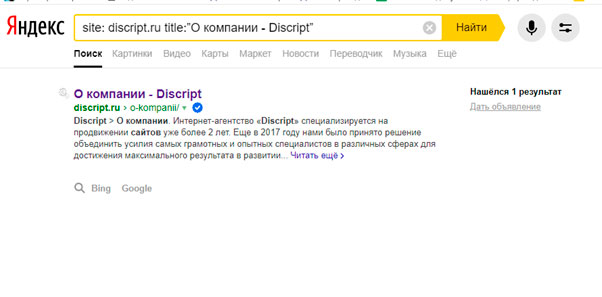
Мы видим, что дублей нет
Для Google:
site: vashdomen.ru intitle:заголовок
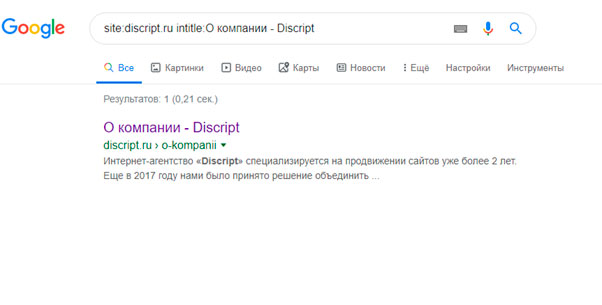
Для Яндекса и Google запрос site:vashdomen.ru inurl:prodvizhenie поможет найти прямое вхождение "prodvizhenie" в URL документов. Но ведь это еще не дубли. А чтобы найти здесь дубли, необходимо выданные поисковиком страницы просмотреть вручную.
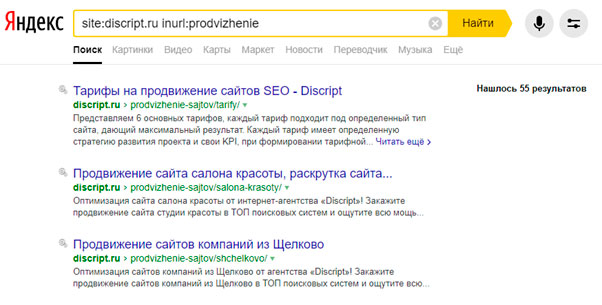
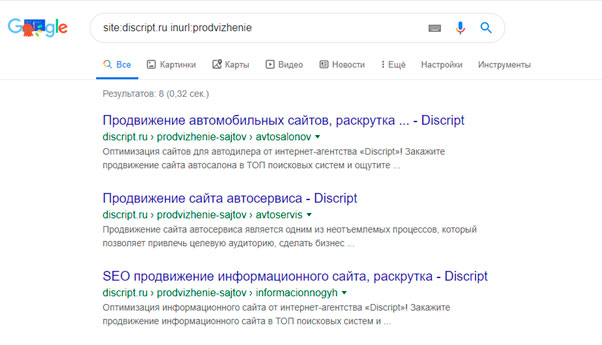
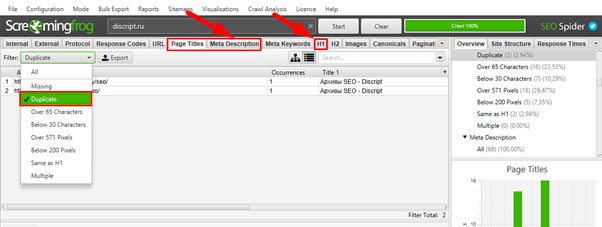
Для поиска дублей можно использовать программу Screaming Frog Seo Spider.Запуская паука на сайт, программа выгружает полный список адресов, который потом можно отсортировать по совпадению тегов description и title и таким образом выявить возможные дубли.
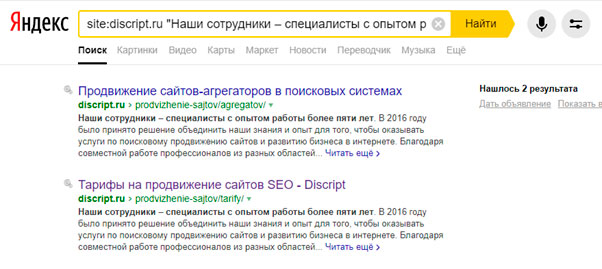
Дубли можно искать также по контенту.
Представленный способ помогает найти неуникальный контент. При этом в title и мета-теги могут быть частично уникальными.Чтобы выявить на сайте подобные страницы, подойдет цитатный поиск или поиск части текста. Для этого нужно ввести запрос: site:vashdomen.ru “текст” и совершить поиск на сайте по части текста страниц. Сам текст при этом вводится в кавычках. Это нужно для того, чтобы найти страницы с точно таким же порядком и формой слов, как в запросе. При этом поиск будет произведен только в рамках сайта. Если же необходимо найти дубли по всему интернету, то оператор “site” указывать не нужно. В таком случае запрос будет иметь вид: "Фраза с проверяемой страницы".
-
Найти частичные дубли можно, используя сервис https://seoto.me. Результат будет выглядеть таким образом:
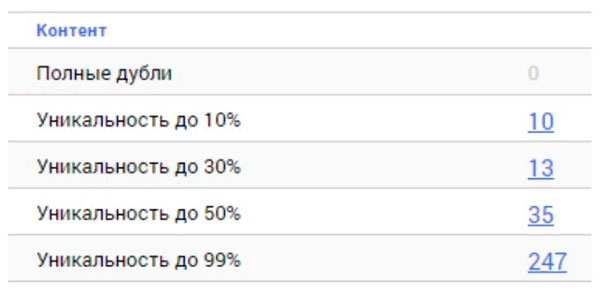
Что делать дальше?
Когда на сайте найдены дубли, остается решить, что именно с ними делать. Здесь также может быть несколько вариантов. Но перед тем, как удалить дубли страниц нужно понять, почему они появились, т.к. простое удаление может не решить проблему в целом, а значит через время появятся новые дубли по тем же причинам.
Оптимальный вариант - настроить 301-редирект на оригинальную страницу.
Если страницы - дубли не удается удалить по каким-то причинам, то нужно указать поисковым роботам, какая именно страница является основной.
Можно запретить индексацию дублей в файле «robots.txt».
Можно установить тег «meta name="robots" content="noindex, nofollow"» в коде страницы в блоке head. При этом важно ,чтобы страница не была закрыта в robots.txt, иначе робот на нее просто не зайдет. Этот тег указывает роботу не индексировать документ и не переходить по ссылкам (но можно и разрешить переходить по ссылкам), и используется для страниц, которые должны продолжить существовать. В отличие от robots.txt, этот метатег - прямая команда, которая не будет игнорироваться роботами. Такой вариант оптимален для печатных версий, табов с отзывами, характеристиками и т.д.
На дубль могут уже вести внешние ссылки, также она может приносить трафик или быть добавлена в закладки пользователями. Если с нее настроен редирект, то тот же пользователь не потеряет сайт, а просто будет перенаправлен на оригинал. Такая настройка производится через редактирование файла-конфигуратора .htaccess или при помощи плагинов. Через некоторое время документ - дубль просто выпадет из индекса, и вся ссылочная масса перейдет основному. Кроме этого, 301- редирект передает и технические характеристики (например, возраст документа, ПФ и т.д.).
Специально для этого был введен атрибут rel=«canonical». Сегодня его понимает и Гугл, и Яндекс. Такой вариант считается лучшим для страниц сортировок, пагинации, фильтров, utm- страниц и клонирования одной позиции в нескольких списках.
Для этого нужно использовать директиву Disallow, которая запрещает поисковому роботу индексацию определенных разделов или типов страниц. Такой способ хорошо подходит для дублей, частично повторяющих контент основных страниц.

Стоит отметить, что, если страница указана в robots.txt с директивой Disallow, то в Google документ все равно может оказаться в выдаче. Например, если она была проиндексирована раньше или на нее есть ссылки. Инструкции robots.txt носят рекомендательный характер для поисковых роботов и не могут дать гарантии удаления дублей.
Для того, чтобы удалить дубли страниц, созданные вручную, нужно сперва проанализировать трафик, который идет на них, определить наличие внешних и внутренних ссылок, а также наличие документов в индекс. Если документа в индексе нет, то его можно удалять с сайта. Если же страницы есть в поисковой базе, то нужно оценить, сколько поискового трафика они дают, сколько внутренних и внешних ссылок на них проставлено и после этого выбрать наиболее полезную. Далее нужно настроить 301- редирект со старой страницы на актуальную и поправить ссылки на релевантные.
Однако лучше всего постараться не допускать появления дублей, т.е. проводить своевременную профилактику. Для этого необходимо найти и устранить уже имеющиеся полные дубли, после чего:
- применить шаблонную оптимизацию,
- или использовать UGC контент.
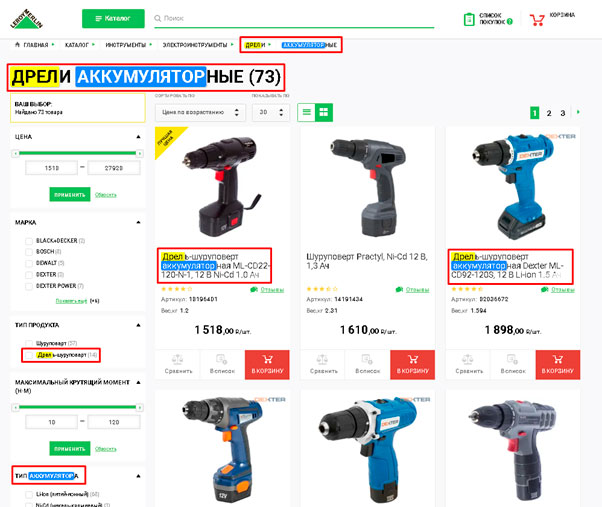
В случае использования шаблонной оптимизации каждая страница будет иметь уникальные вхождения за счет переменной, которая является ключом для нее:
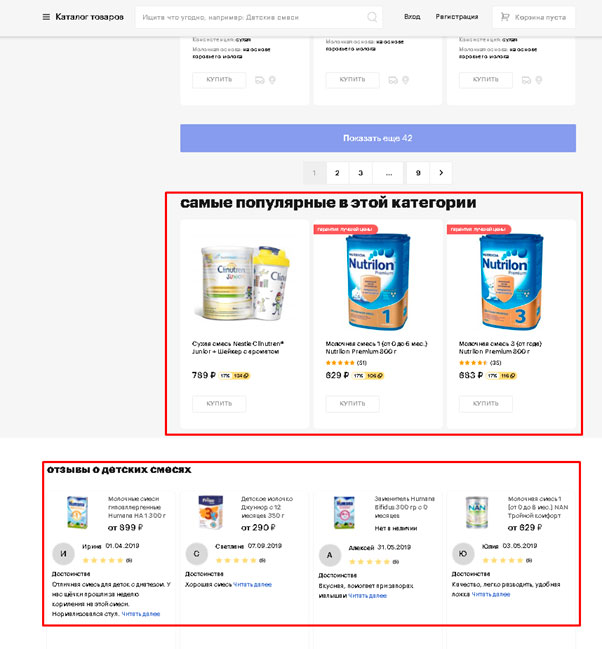
Использование UGC контента подразумевает уникализацию страниц путем выведения уникальных фрагментов. Это могут быть отзывы, которые оставляют сами пользователи, видео обзоры и т.д.
Например, отзывы на странице: https://goods.ru/catalog/detskie-smesi/
Дубли - не самое приятное явление и с ними нужно бороться. Они плохо влияют на ссылочный вес, ухудшают поведенческие факторы и совсем неблагоприятно сказываются на ранжировании. Поэтому рекомендуем регулярно проверять страницы, попадающие в индекс, и проводите своевременную профилактику.
А мы желаем вам успехов в борьбе с дублями и предлагаем перейти к следующей статье в нашем блоге - "Удаление контента 404 или 410. Какой код ответа настроить?". Долгое время не утихают споры о том, какой код и в какой ситуации правильнее отдавать - 404 или 410? В чем их отличие и есть ли оно? Что говорят об этом сами представители поисковых систем? Читайте обо всем этом в нашей следующей статье.



