Screaming Frog SEO spider — незаменимый помощник SEO-оптимизатора при внутреннем техническом анализе веб-сайтов. В программе есть множество функций, о которых мы расскажем в этой статье. Также в конце приведем конкретные примеры, как можно применять разные опции в работе.
Прочитав инструкцию, вы научитесь использовать нужные инструменты, предоставляемые сервисом, для технического аудита сайтов. В будущем это может пригодиться при выявлении технических ошибок и составлений ТЗ на доработку сайта.
Для начала рассмотрим по порядку все вкладки интерфейса программы.
Содержание:
File
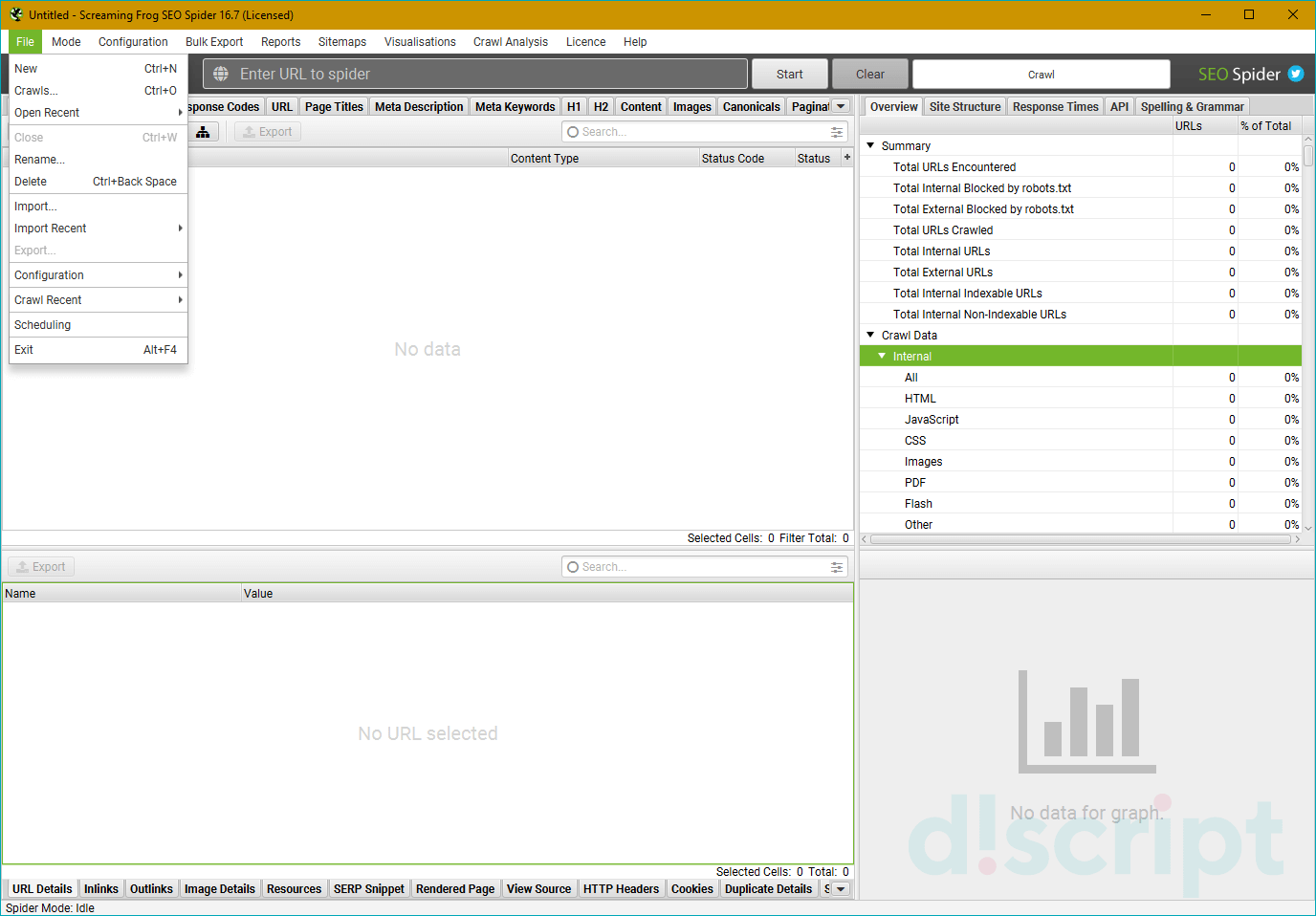
Раздел, предназначенный для работы с файлами — загрузкой проектов и конфигураций, планирования будущих проверок и т.д.
Доступные опции:
- Open — используется для загрузки и открытия файла с ранее проводившимся парсингом.
- Open Recent — похожая функция, но открывает последний проведенный парсинг. То есть, Open можно использовать для открытия любых файлов, а Open Recent — для последнего файла.
- Save — сохранение парсинга.
- Configuration — важный параметр, позволяющий загружать и/или сохранять конфигурации — специальные предварительно заданные настройки с параметрами парсинга. Подробнее расскажем в разделе про Configuration.
- Crawl Recent — используется для повторного парсинга последнего сайта, который ранее проверялся. Удобно, если нужно быстро провести второй технический аудит.
- Scheduling — применяется для планирования будущих парсингов и других задач программы.
- Exit — очевидный выход.
Mode
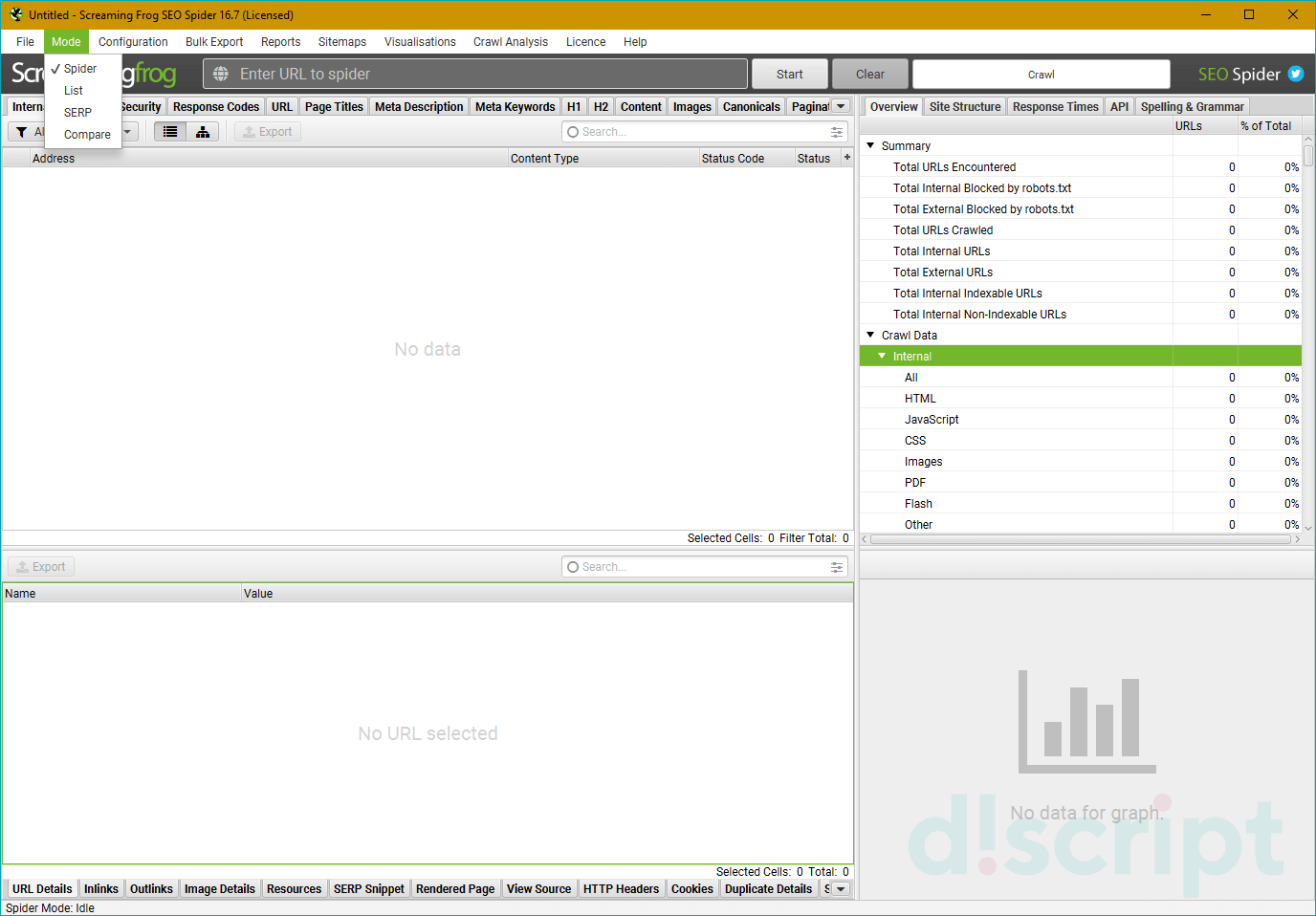
Устанавливает режим, в котором будет проводиться парсинг. Можно выбрать 1 из 3 опций:
- Spider — режим по-умолчанию. Парсинг будет проводиться по внутренним линкам. Для старта достаточно ввести в адресную строку приложения нужный домен.
- List — парсинг предварительно собранных URL. Сами веб-адреса можно загрузить из файла (опция From a file), указать вручную (Enter Manually) или воспользоваться картой сайта (Download Sitemap).
- SERP Mode — позволяет загрузить мета-данные с сайта и редактировать их, посмотреть, как они будут отображаться в браузере. Сканирование при этом не проводится.
Configuration
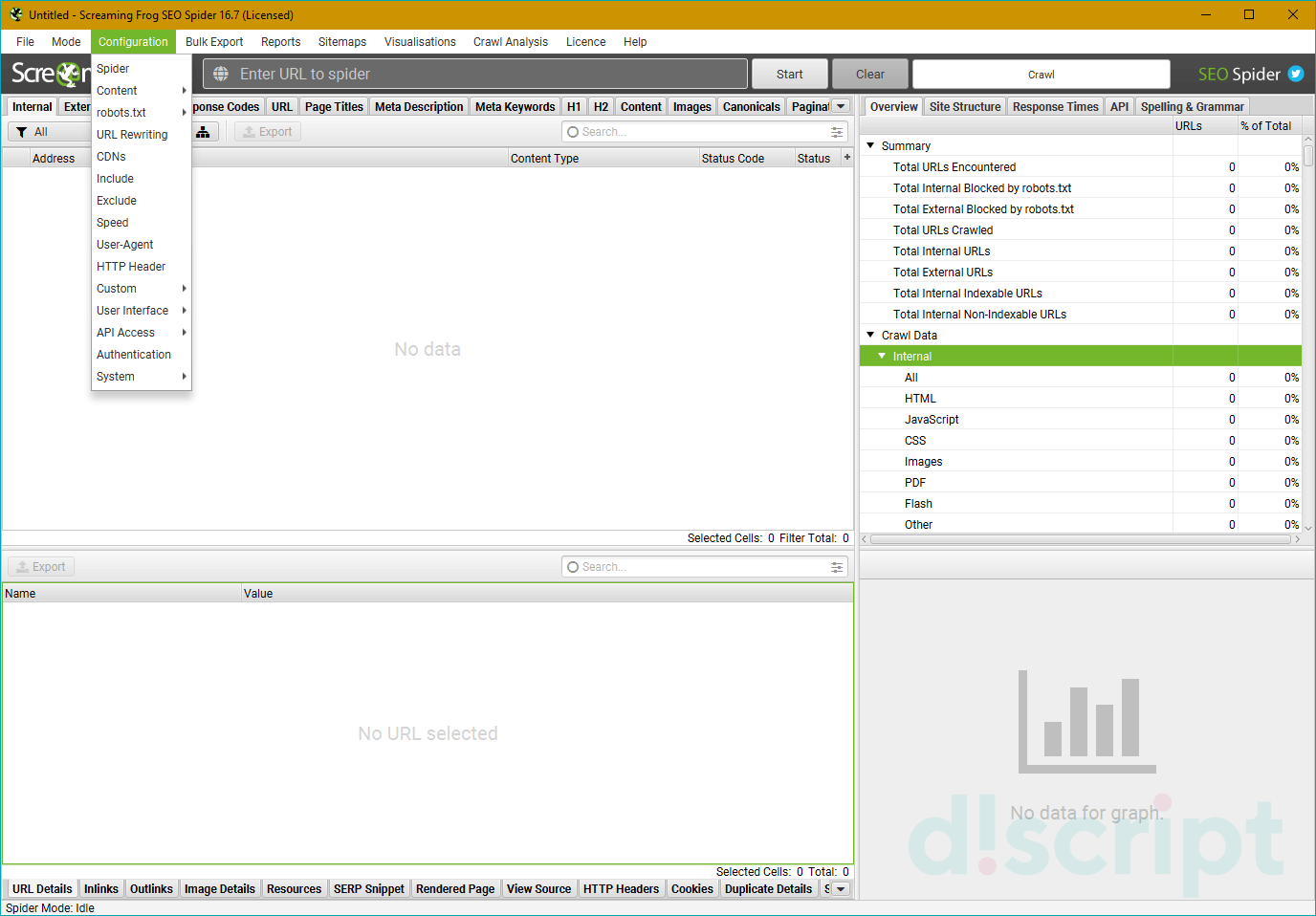
Одна из самых обширных вкладок — в ней расположены основные настройки «паука» и опции по парсингу сайтов. Всего в ней доступно 13 пунктов подменю. Рассмотрим каждый подробнее.
Spider
В этом подпункте расположены основные настройки парсингов сайта. Включает в себя 5 вкладок: Crawl, Limits, Rendering, Advanced и Preferences.
Crawl
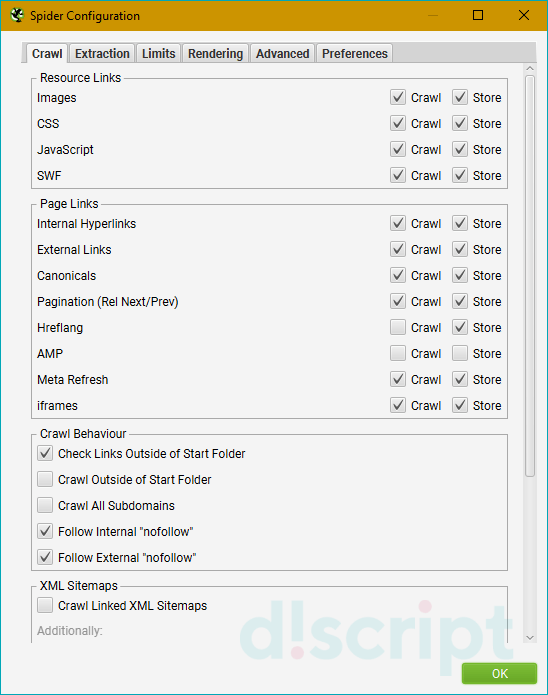
Позволяет выбрать, что именно и как вы хотите парсить. Основные опции вкладки разделены на 4 блока:
Resource Links — определяют, какие файлы и элементы будут парситься. Включают в себя 4 опции:
- Check Images — парсит картинки.
- Check CSS — парсит подключенные к сайту файлы CSS.
- Check JavaScript — парсит JS-скрипты.
- Check SWF — применяется, когда нужно включить в отчет анализ Flash-анимаций.
Page Links — определяют, какие ссылки будут парситься. В этом разделе доступны следующие опции:
- Internal Hyperlinks — добавляет в отчет внутренние ссылки.
- External Links — добавляет в отчет внешние ссылки.
- Canonicals — при сканировании веб-страниц будут анализироваться канонические (canonical) параметры.
- Pagination (Rel Next/Prev) — используется для анализа страниц с атрибутами rel = next и rel = prev.
- Hreflang — извлекает атрибут hreflang.
- AMP — извлекает с сайта и добавляет в отчет AMP-ссылки.
- Meta Refresh — сканирует и сохраняет URL-адреса, содержащиеся в мета-обновлениях
(например, такие: <meta http-equiv="refresh" content="5; url=https://example.com/&quot; />.).
- iframes — сканирует и сохраняет адреса, содержащиеся в теге <iframe> (например, такие: <iframe
src="htttps://example.com">.
Crawl Behaviour — определяет поведение краулера. Доступные опции:
- Check Links Outside of Start Folder — активируйте эту опцию, если хотите получить анализ всех линков, а не только тех, что расположены в стартовой папке.
- Crawl Outside of Start Folder — стандартно программа будет сканировать только указанную пользователем подпапку. Включение этой опции позволяет сканировать весь сайт. При этом парсинг все равно начнется с поддомена.
- Crawl All Subdomains — активируйте эту опцию, если хотите сканировать все поддомены веб-сайта.
- Follow internal «nofollow» — позволяет сканировать ссылки с тегом nofollow.
- Follow external «nofollow» — по принципу действия почти та же опция, что и предыдущая, но вместо внутренних ссылок анализирует внешние.
XML Sitemaps — отвечает за сканирование карты сайта. Здесь доступна всего 1 опция и 2 подпункта для неё:
- Crawl Linked XML Sitemap — сканирует карту сайта. Поисковый робот может либо взять ее из файла robots.txt (опция Auto Discover SML Sitemaps via robots.txt), либо по ручному пути, указанному пользователем — тогда вам нужно будет выбрать опцию «Crawl These Sitemaps» и указать нужные.
Также все опции имеют 2 опции — «Crawl» и «Store». Первая отвечает за сканирование. Если отключить ее в каком-либо элементе, он не будет анализироваться пауком. Например, сняв флажок со сканирования ссылок, вы позволите поисковому роботу обнаруживать их и хранить, но не переходить по ним и не получать коды ответов сервера.
Поначалу может показаться, что опций слишком много, но главное в освоении этой программы — практика и умеренность. Выбирайте те, которые могут пригодиться вам в работе, а с остальными познакомитесь по ходу использования приложения.
Extraction
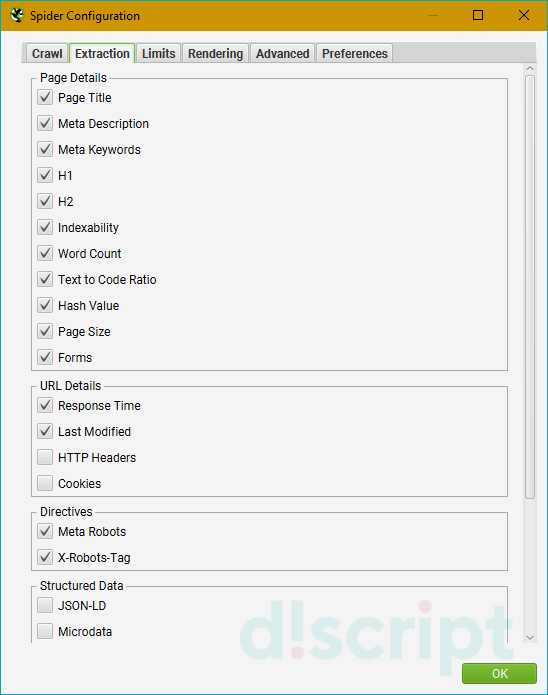
Вкладка отвечает за то, какие элементы будут извлекаться парсером и добавляться в отчет. Разделена на 5 секций:
Page Details
Отвечает за извлечение следующих элементов:
- Page Title — метатег title.
- Meta Description — метатег description.
- Meta Keywords — метатег keywords.
- H1 — заголовок 1 уровня.
- H2 — заголовок 2 уровня.
- Indexability — статус индексируемости.
- Word Count — количество слов.
- Text to Code Ratio — соотношение текста к коду.
- Hash Value — хэш-значение.
- Page Size — размер страницы.
- Forms — формы.
URL details
- Response Time — время в секундах для загрузки URL-адреса.
- Last Modified — чтение из заголовка Last-Modified в HTTP-ответе сервера. Если сервер не предоставит ответ, поле останется пустым.
- HTTP Headers — полные заголовки запросов и ответов HTTP.
- Cookies — файлы cookie, найденные во время сканирования. Будут храниться на нижней вкладке отчета «Cookies files».
Directives
- Meta Robots — сохраняет директиву мета-роботов.
- X-Robots Tag — добавляет в отчет директиву X-Robots-Tag.
Structred Data
- JSON-LD — используется для извлечения микроразметки JSON-LD.
- Microdata — извлекает микроразметку сайта Microdata.
- RDFa — извлекает RDF микроразметку.
- Schema.org Validation —настраивает проверку микроразметки по механизму Schema Validation.
- Google Rich Result Feature Validation — включает проверку по Google Validation.
- Case-Sensitive — активирует проверку по Case-Sensitive методу.
HTML
- Store HTML — позволяет хранить статический HTML каждого URL, просканированного парсером. Полезно, если нужно изучить его до того, как будет подключен JavaScript.
- Store Rendered HTML — похожая опция, но хранится уже отображенный HTML после обработки JS.
Limits
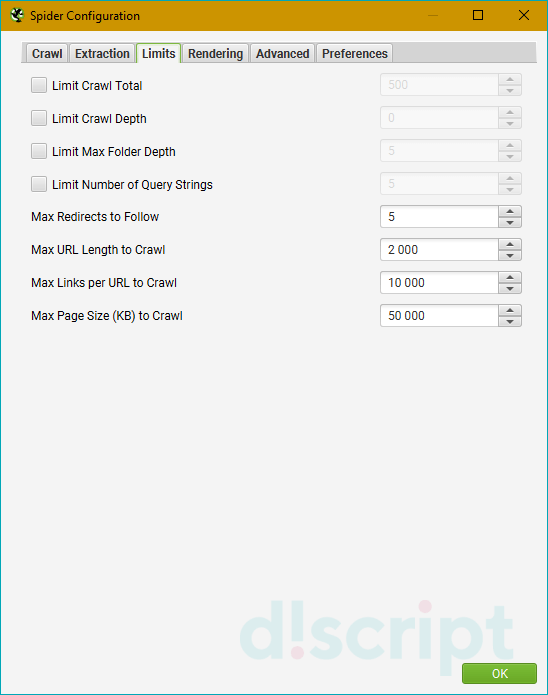
Применяется для установки лимитов парсинга. Содержит пункты:
- Limit Crawl Total — задает общий лимит веб-страниц для сканирования. С помощью этой опции можно установить точное количество страниц, которые будут выгружены в отчет.
- Limit Crawl Depth — определяет, насколько глубоко может зайти поисковый робот во время сканирования. Например, если указать число «0», краулер просканирует только указанный документ и остановится. Если указать «1», паук проанализирует документ, перейдет по ссылкам из него и остановится на следующей странице. Указав «2», робот продвинется на 3 страницы (первичный документ > переход на следующую страницу по ссылкам > переход на последующую веб-страницу по ссылкам из предыдущей).
- Limit Max Folder Depth — более специфический параметр, в котором можно установить глубину до конкретной папки. Работает по принципу, схожему с предыдущим пунктом, только указывать нужно конкретные папки. Пример: URL site.com/folder-1/folder-2/folder-3. Где цифры — глубина проверки.
- Limit Number of Query Strings — задает глубину парсинга для страниц с параметрами. Может быть полезно, если у вас на статической странице есть пара фильтров, которые могут создать большое количество динамических веб-страниц. Если не задать этот лимит, парсер будет сканировать все страницы, что увеличит время проверки, при этом полезной информации вы получите по-минимуму.
- Max Redirects to Follow — используется, чтобы задать максимальное количество редиректов с 1 веб-адреса.
- Max URL Length to Crawl — устанавливает максимальную длину URL в символах.
- Max Links per URL to Crawl — определяет максимальное количество ссылок в сканируемых страницах. Например, если на странице 5 ссылок, но параметр установлен на «4», то робот проанализирует 4 ссылки и добавит их в отчет.
- Max Page Size (KB) to Crawl — максимальный размер страницы для сканирования, указывается в килобайтах.
Rendering
Эта вкладка понадобится вам, если вы включили сканирование JavaScript в отчет и хотите настроить параметры рендеринга. На выбор доступно 3 режима:
- Text Only — анализ только текста страницы, без учета JS/AJAX.
- Old AJAX Crawling Scheme — использование устаревшей схемы сканирования AJAX.
- JavaScript — учитывает JS-скрипты при рендеринге.
Последний режим также имеет несколько дополнительных опций:
- Enable Rendered Page Screen Shots — позволяет включить сохранение скриншотов анализируемых страниц в папку на вашем компьютере.
- AJAX Timeout (secs) — устанавливает лимиты таймаута.
- Window Size — выбирает размер окна. На выбор их представлено много, от больших экранов (Large Desktop) до iPhone старых и новых версий.
- Sample — показывает пример окна, выбранный в пункте Window Size.
- Rotate — позволяет повернуть демонстрацию окна из Sample.
Advanced
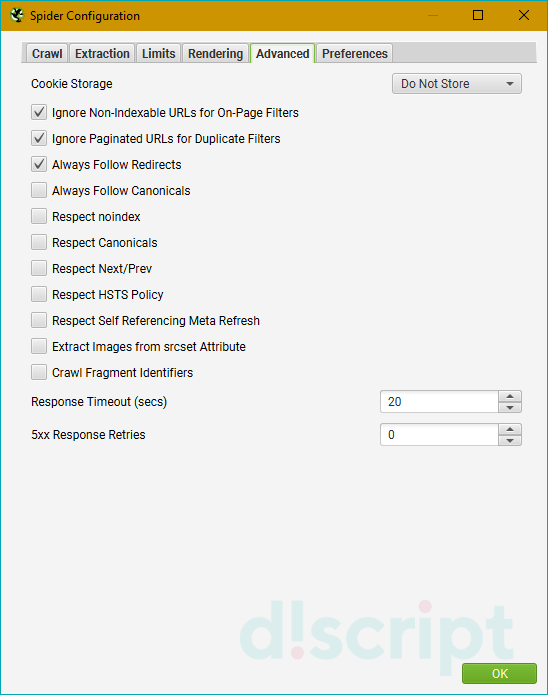
Позволяет настроить продвинутые опции парсинга. Доступные опции:
- Cookie Storage — выбирает, где будут храниться куки-файлы во время сканирования.
- Ignore Paignated URL for Duplicate Filters
- Always Follow Redirects — разрешает поисковому роботу всегда следовать по редиректам вплоть до финальной страницы с учетом всех ответов сервера.
- Always Follow Canonicals — позволяет краулеру учитывать все атрибуты canonical. Может пригодиться, если вы несколько раз переезжали и еще не навели порядок с этим атрибутом.
- Respect noindex — запрещает сканировать страницы, обернутые в тег noindex.
- Respect Canonical — исключает канонические страницы из отчета. Полезная опция, если нужно убрать дубли по метаданным.
- Respect Next/Prev — исключает страницы с rel=”next/prev” из отчета. Так же, как и предыдущий пункт, позволяет убрать дубли по метаданным.
- Respect HSTS Policy — указывает поисковому боту, что все запросы должны выполняться через протокол HTTPS.
- Respect Self Referencing Meta Refresh — позволяет учитывать принудительную переадресацию на ту же страницу по метатегу Refresh.
- Extract Images from img srcset Attribute — извлекает и добавляет в отчет изображения из атрибута srscet,
который прописывается в теге
.
- Crawl Fragment Identifiers — позволяет сканировать URL-адреса с хэш-фрагментами и считать их за уникальные URL.
- Response Timeout — устанавливает время ожидания ответа страницы перед тем, как краулер перейдет к анализу следующего URL. Для медленных сайтов рекомендуем устанавливать большее число.
- 5xx Response Retries — определяет, сколько раз парсер будет пытаться проанализировать страницы с ответом сервера 5хх. Например, если установлен параметр «5», то поисковый робот будет посылать запросы веб-странице 5 раз, после чего остановится.
Preferences
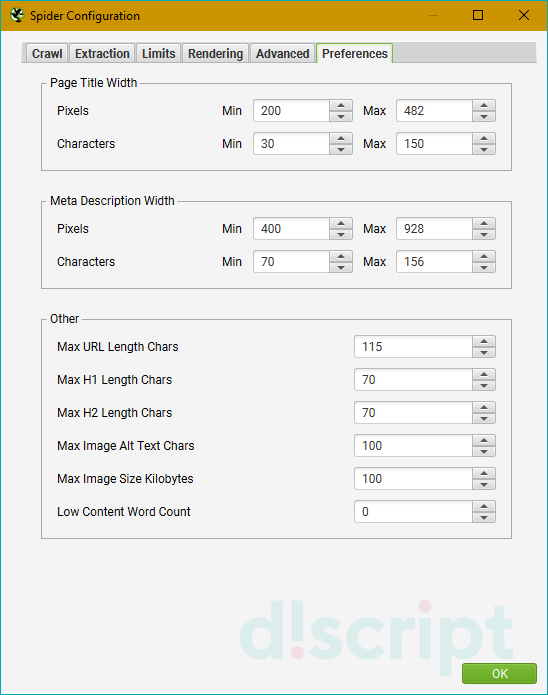
Позволяет задать предпочтения для сканируемых мета-тегов и тегов (title, description, URL, H1-H2, alt и размеры картинок). Если размеры будут не соответствовать заданным в этой вкладке, Screaming Frog об этом сообщит.
Доступные опции:
- Page Title Width — ширина заголовка страницы. Можно указать в пикселях или символах.
- Meta Description Width — аналогично предыдущему пункту, только вместо заголовка указывается метатег title.
- Other — все остальные пункты, включая URL, заголовки 1 и 2 уровней, изображения и атрибуты alt к ним.
Не обязательная вкладка, в ней можно оставить параметры по умолчанию.
Content
Подпункт меню, отвечающий за поведение краулера при сканировании контента. Имеет 3 вкладки:
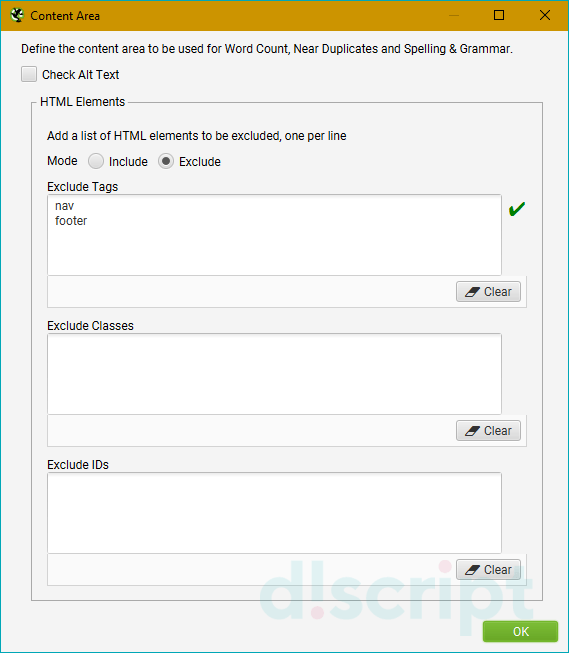
- Area — отвечает за область контента, которая будет учитываться при сканировании. Используйте эту
функцию, если хотите сфокусировать анализ на какой-либо конкретной области страницы.
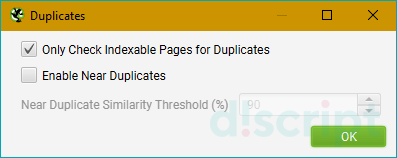
- Duplications — позволяет найти точные дубликаты страниц или веб-страницы, контент на которых
совпадает в некоторых местах. Помогает в поиске дублей.
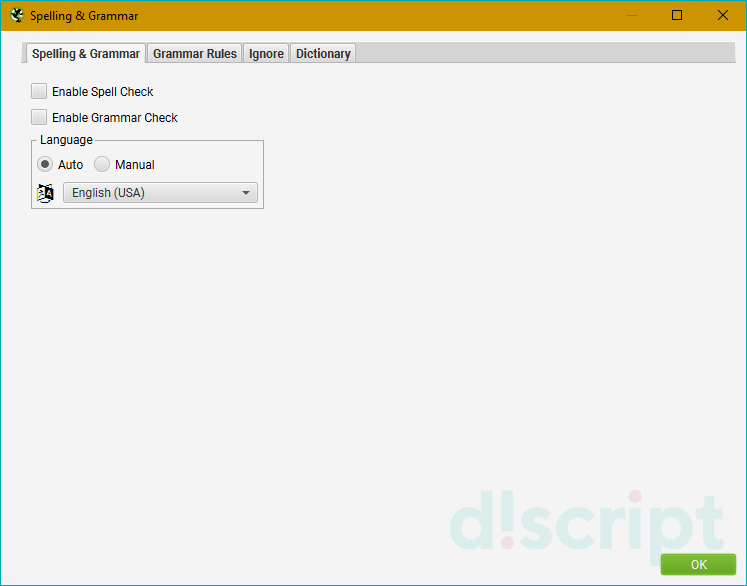
- Spelling & Grammar — проверяет правописание и грамматику. Поддерживает 39 языков, включая
русский. По-умолчанию эта функция отключена.
Robots.txt
Позволяет определить, каким правилам должен следовать краулер при парсинге. Имеет 2 вкладки: Settings и Custom.
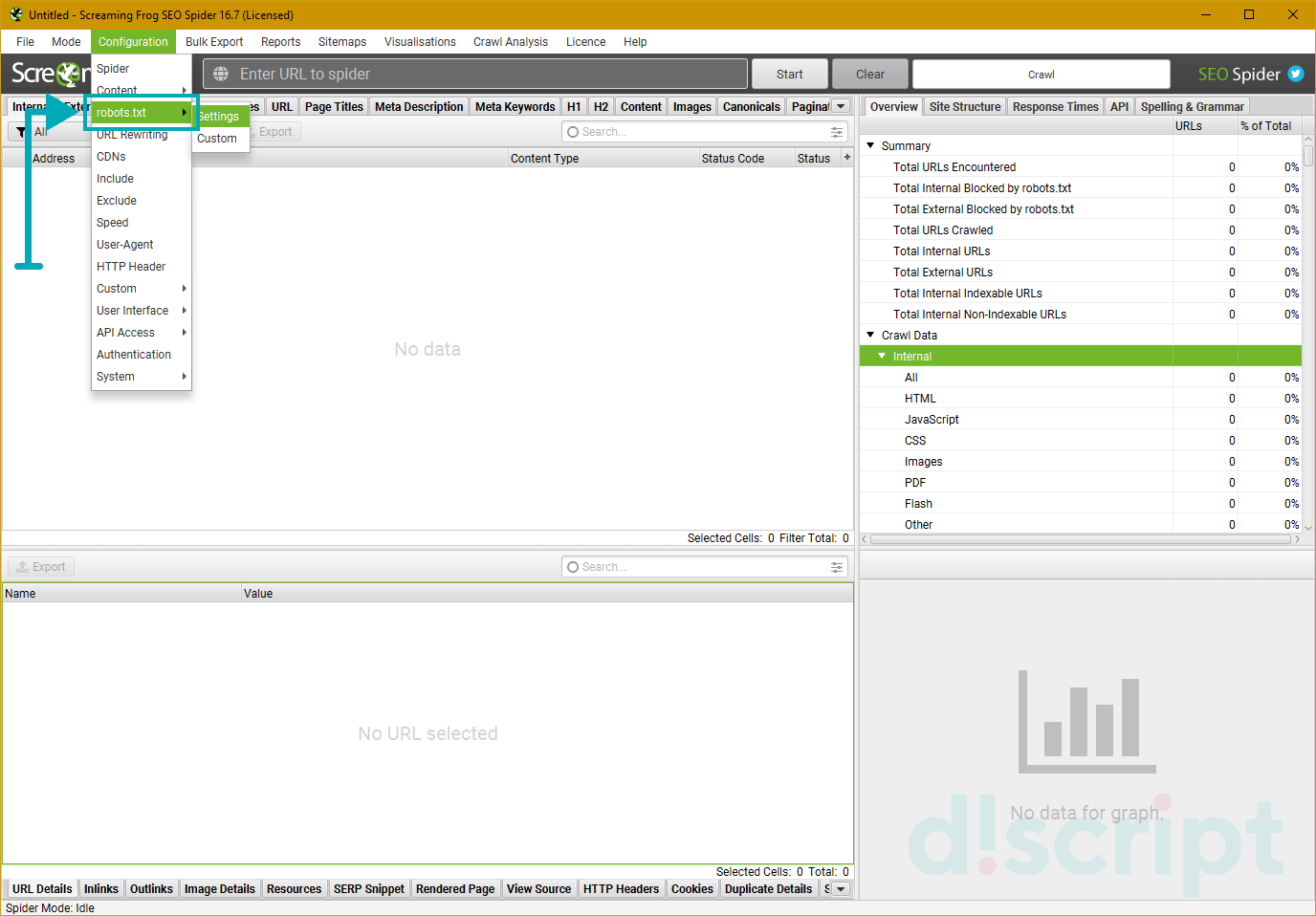
Settings — используется для настройки парсинга с учетом (или игнорированием) правил Robots.txt. На выбор предоставляется 3 режима:
- Respect robots.txt — парсер будет полностью следовать правилам, прописанным в файле для роботов, и учитывать только те папки и файлы, которые были открыты.
- Ignore robots.txt — позволяет игнорировать правила, прописанные в robots. В таком случае, в отчет попадут все папки и файлы сайта.
- Ignore robots.txt but report status — игнорирует правила, но выводит статус страницы (индексируемая или закрытая от индексации).
Также можно указать, хотите ли вы видеть в итоговом отчете внутренние и внешние ссылки, закрытые от индексации. Эти опции будут работать, только если вы выбрали 1-й режим парсинга (respect robots.txt).
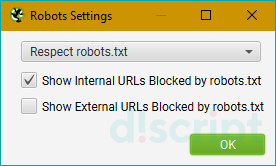
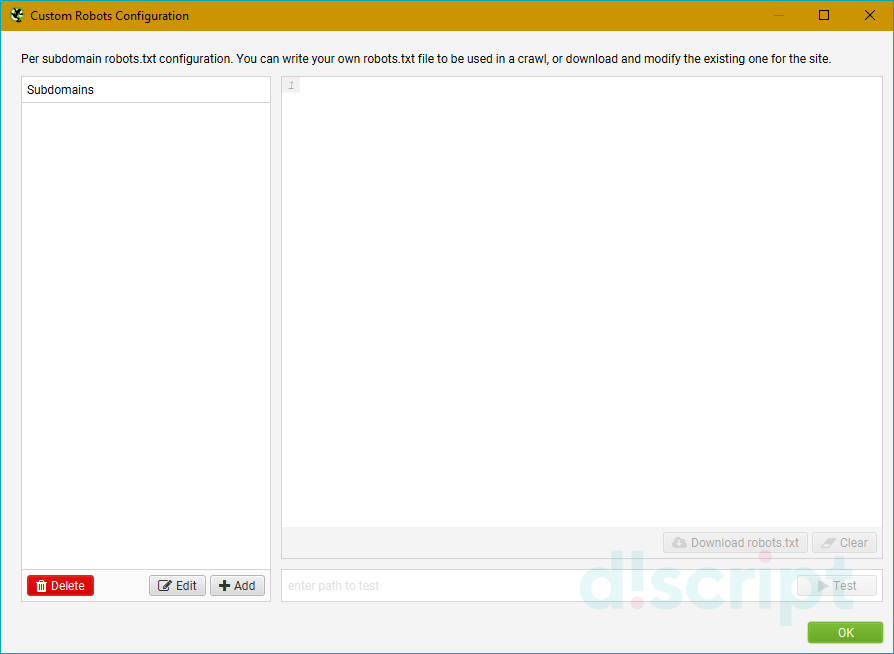
Custom — позволяет вручную отредактировать robots.txt для текущего парсинга. Удобно, если нужно добавить или исключить только конкретные папки, или добавить дополнительные правила для поддоменов сайта. Также с помощью этого режима можно сформировать собственный файл robots.txt, проверить его и потом при необходимости загрузить на веб-сайт.
Чтобы добавить собственный файл, нажмите кнопку «Add» в нижнем меню. Для проверки используйте кнопку «Test», расположенную справа внизу.
URL Rewriting
Используется для перезаписи сканируемых URL во время парсинга. Если вам надо изменить какие-либо URL во время работы, этот раздел может пригодиться.
Имеет 4 вкладки:
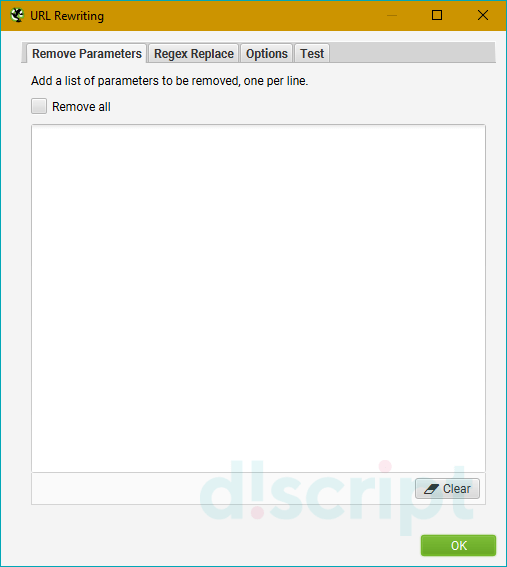
- Remove Parameters — позволяет указать параметры, которые будут удаляться из URL при анализе сайта.
Также можно исключить сразу все, если поставить галочку в чекбоксе «Remove all».
- Regex Replace — позволяет изменить сканируемые URL с использованием регулярных выражений.
Применяется, например, для изменения ссылок с HTTP на HTTPS.
- Options — здесь можно активировать перезапись прописных URL в строчные.
- Test — позволяет сразу увидеть, как будет выглядеть URL при использовании опции Regex Replace.
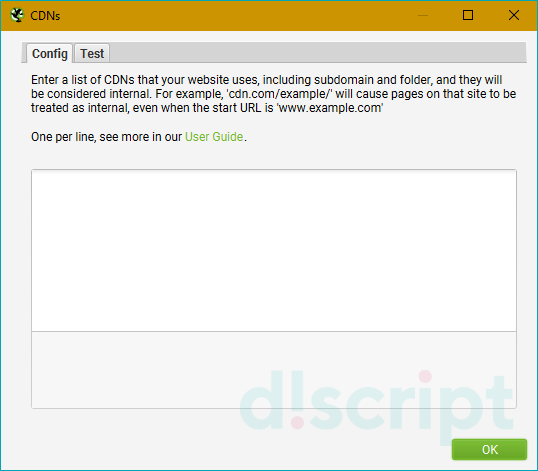
CDNs
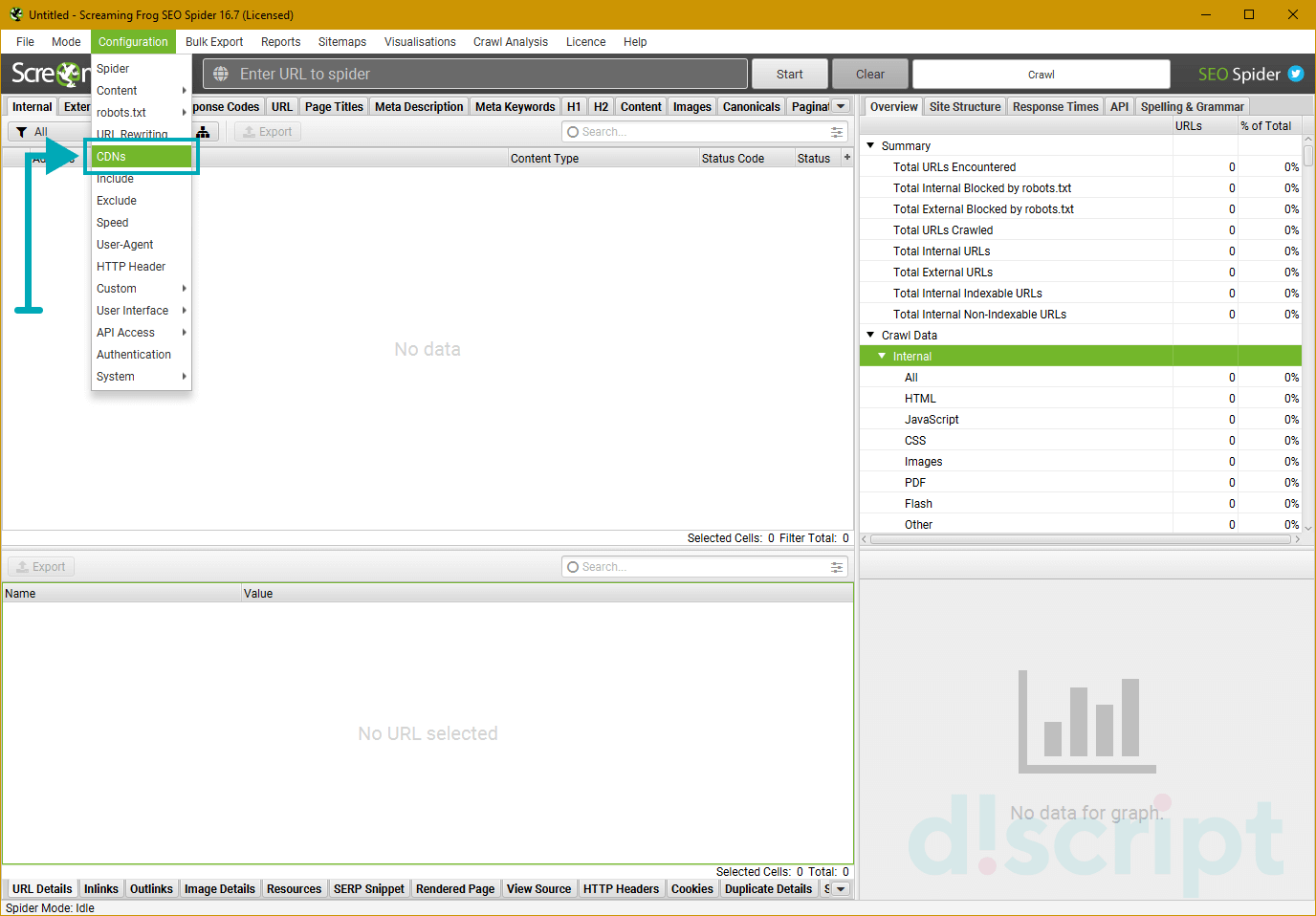
В этой вкладке можно включать дополнительные домены и папки в процесс парсинга. Они будут считаться за внутренние ссылки. Также можно указать только конкретные папки для сканирования. Указывать нужные папки и файлы необходимо во вкладке «Config»:
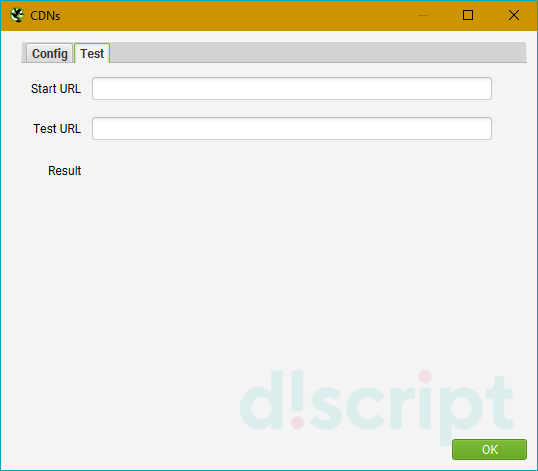
Последняя вкладка «Test» позволяет увидеть, как будут изменяться URL. Итог будет выводиться в виде параметра Internal или External. Если, например, в результате показывает External, то ссылка будет считаться внешней:
Include/Exclude
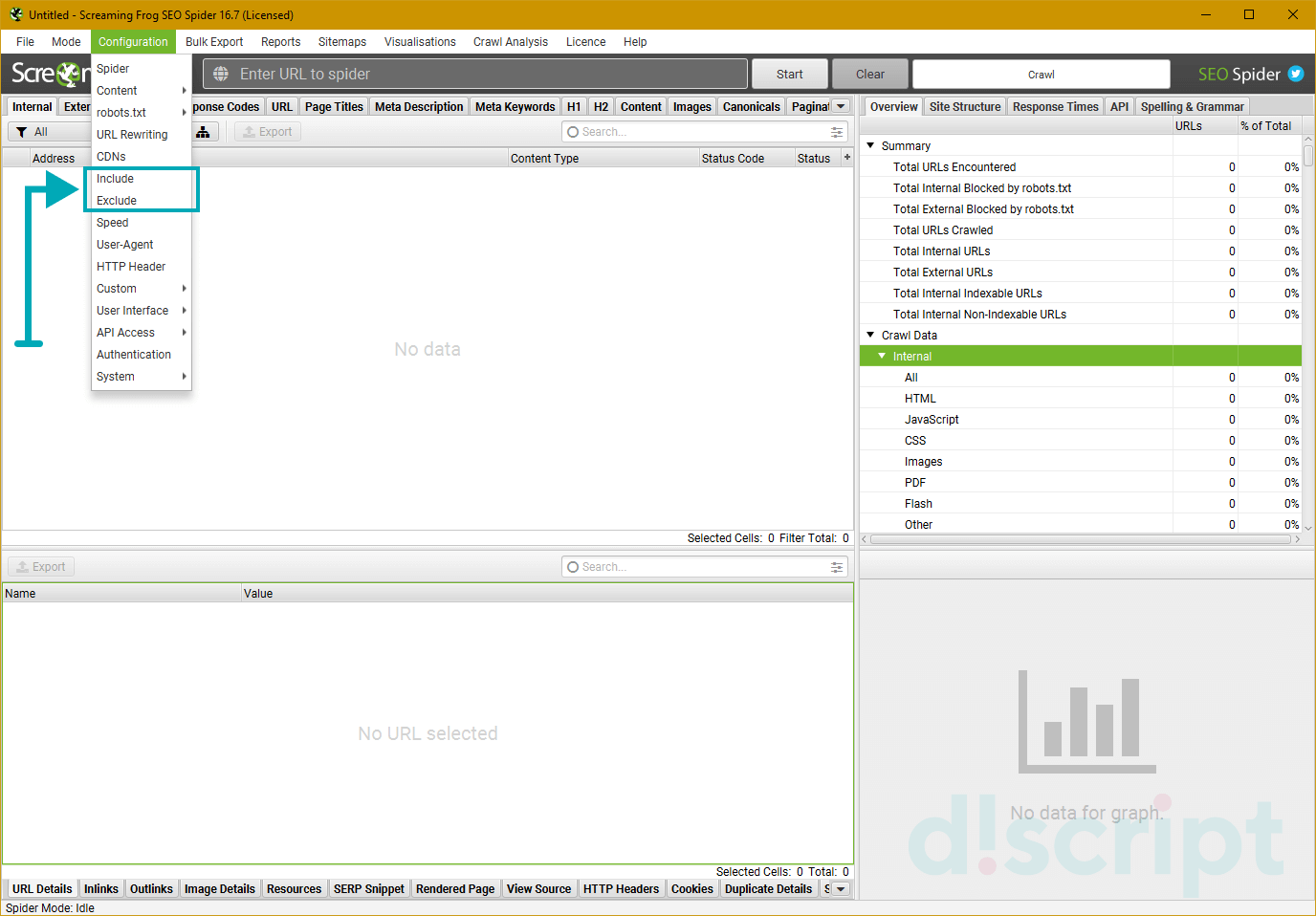
Используется для включения или исключения конкретных папок, ссылок, файлов или страниц при парсинге. Например, во вкладке Exclude будут указаны исключения парсинга для всех папок, кроме указанных.
К примеру, вы можете запретить парсинг конкретного домена. Проверить результат можно во вкладке Test — вместо указанного URL там будет указано, что этот веб-адрес был исключен из парсинга. Также эта опция поддерживает регулярные выражения.
Speed
Используется для установки лимитов на количество потоков и одновременно сканируемых адресов. Меняйте параметры аккуратно — если установить слишком низкие лимиты, поискового бота могут забанить, даже если скорость парсинга существенно повысится.
User-Agent
В этой вкладке можно задать тип поискового бота, который будет использоваться для сканирования. Может пригодиться, если, например, в настройках сайта запрещена индексация Yandex-ботам.
Также можно указать версии ботов для смартфонов, чтобы найти технические ошибки в мобильных версиях.
HTTP Header
Позволяет указать реакции краулера на HTTP-заголовки, если таковые будут найдены на сайте. Можно указать, будет ли учитываться контент и cookie-файлы, как именно они будут обрабатываться и т.д.
Custom
Включает в себя 2 вкладки: Search и Extraction. В них можно указать с помощью собственного кода дополнительные правила для парсинга. Например, если у вас на какой-то странице используется тег <i> вместо тега <em>, вы можете указать это в Custom Search.
Во вкладке Extraction можно указывать пользовательские настройки для извлечения любой информации из HTML-кода.
User Interface
Довольно простой раздел, с помощью которого можно сбросить сортировку столбцов и вкладок программы. Также в нем можно изменить тему со светлой на темную. На этом функции заканчиваются.
API Access
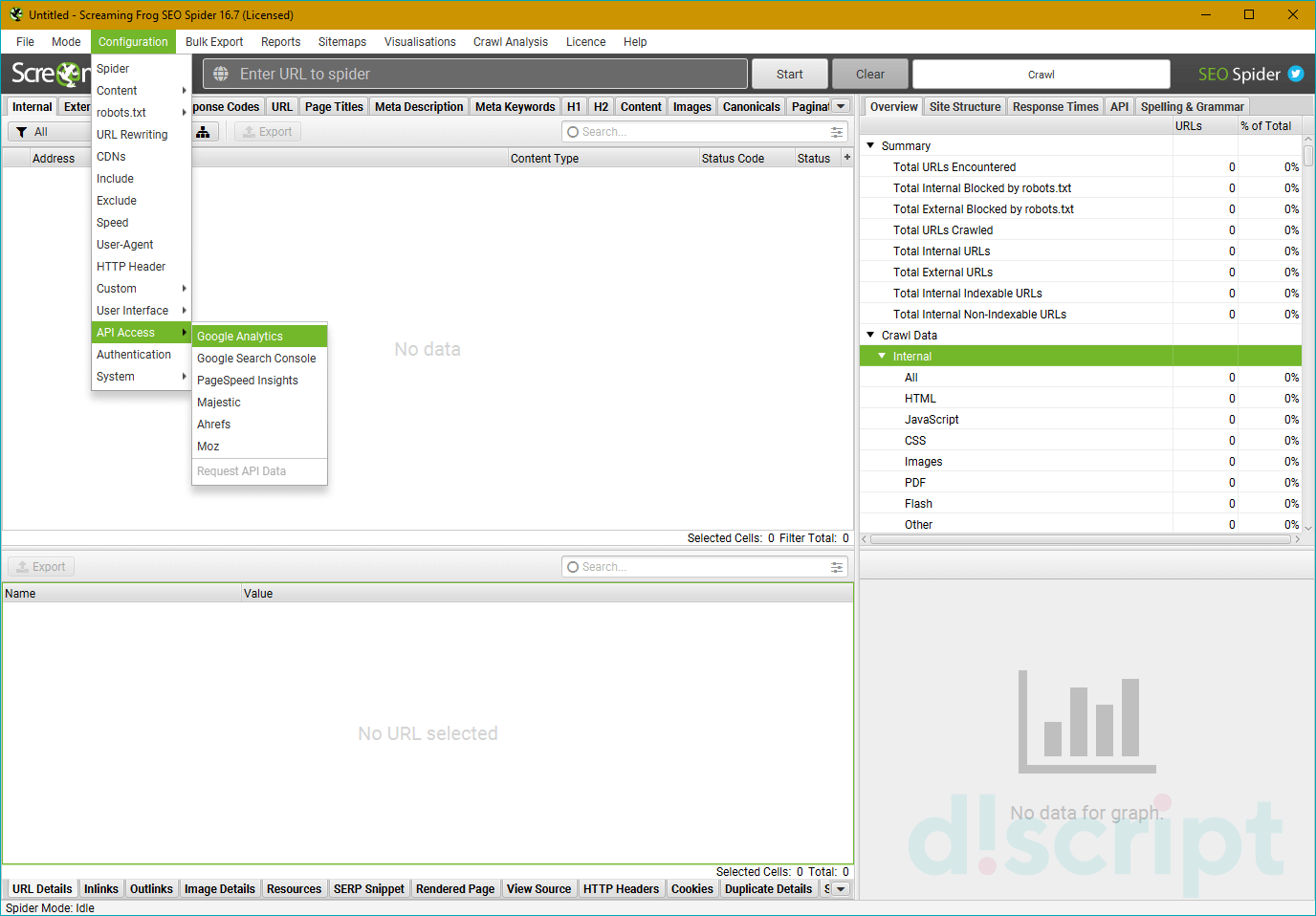
Позволяет подключить сторонние сервисы типа Google Analytics или Majestic. Вам потребуется войти в свою учетную запись в приложении. Для каждого варианта будут свои отдельные настройки по выгрузки данных, которые будут различаться от приложения к приложению.
Authentication
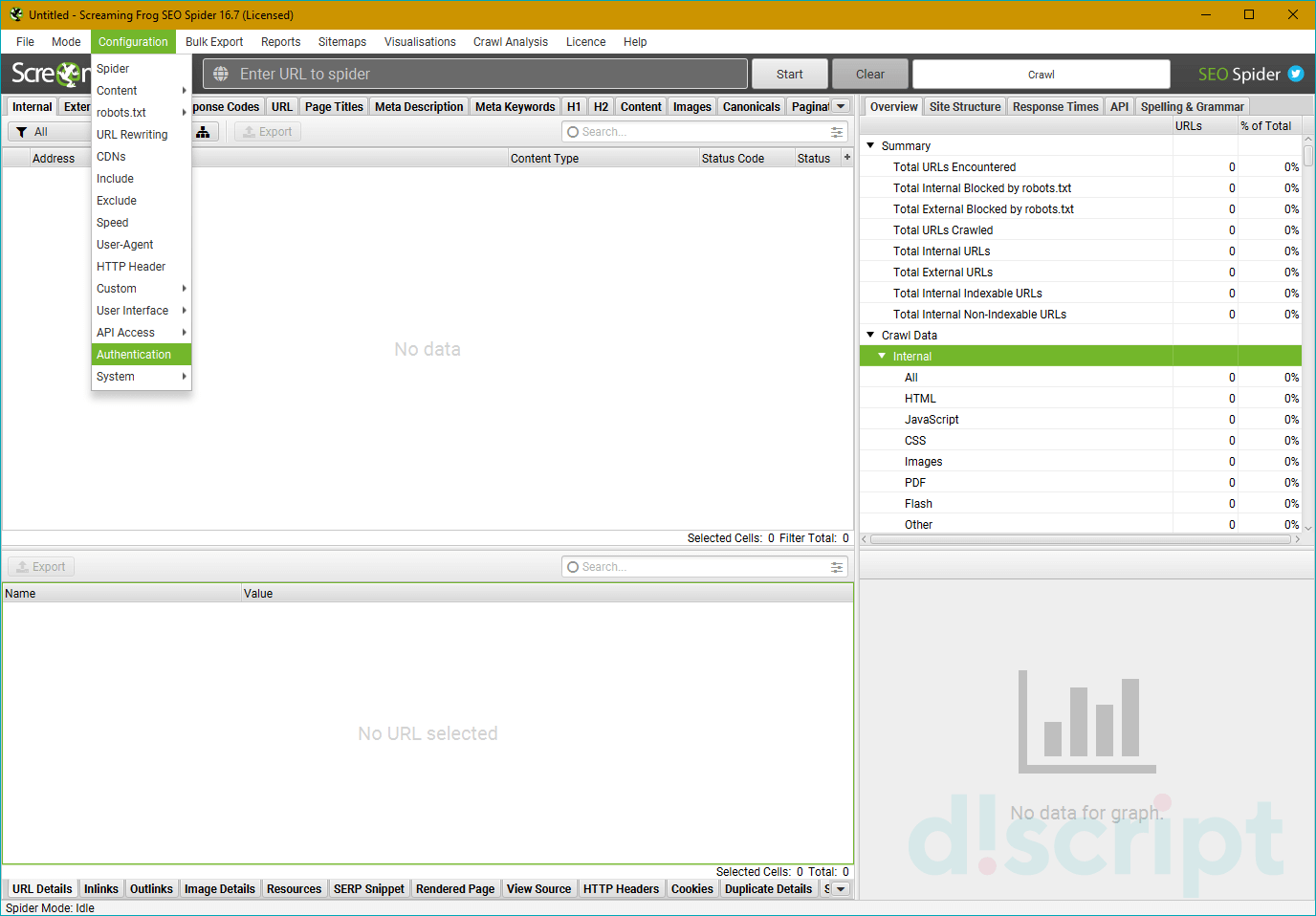
Если сайт будет запрашивать аутентификацию, вы можете указать настройки для них тут. Во вкладке есть 2 подпункта — Standards Based и Forms Based. Стандартно используется первый вариант — если придет запрос, он отобразится в соответствующем окне в программном обеспечении.
Если вам нужен встроенный браузер для указания данных, используйте опцию Forms Based. С ее помощью можно, например, пройти капчу, указав логин и пароль.
System
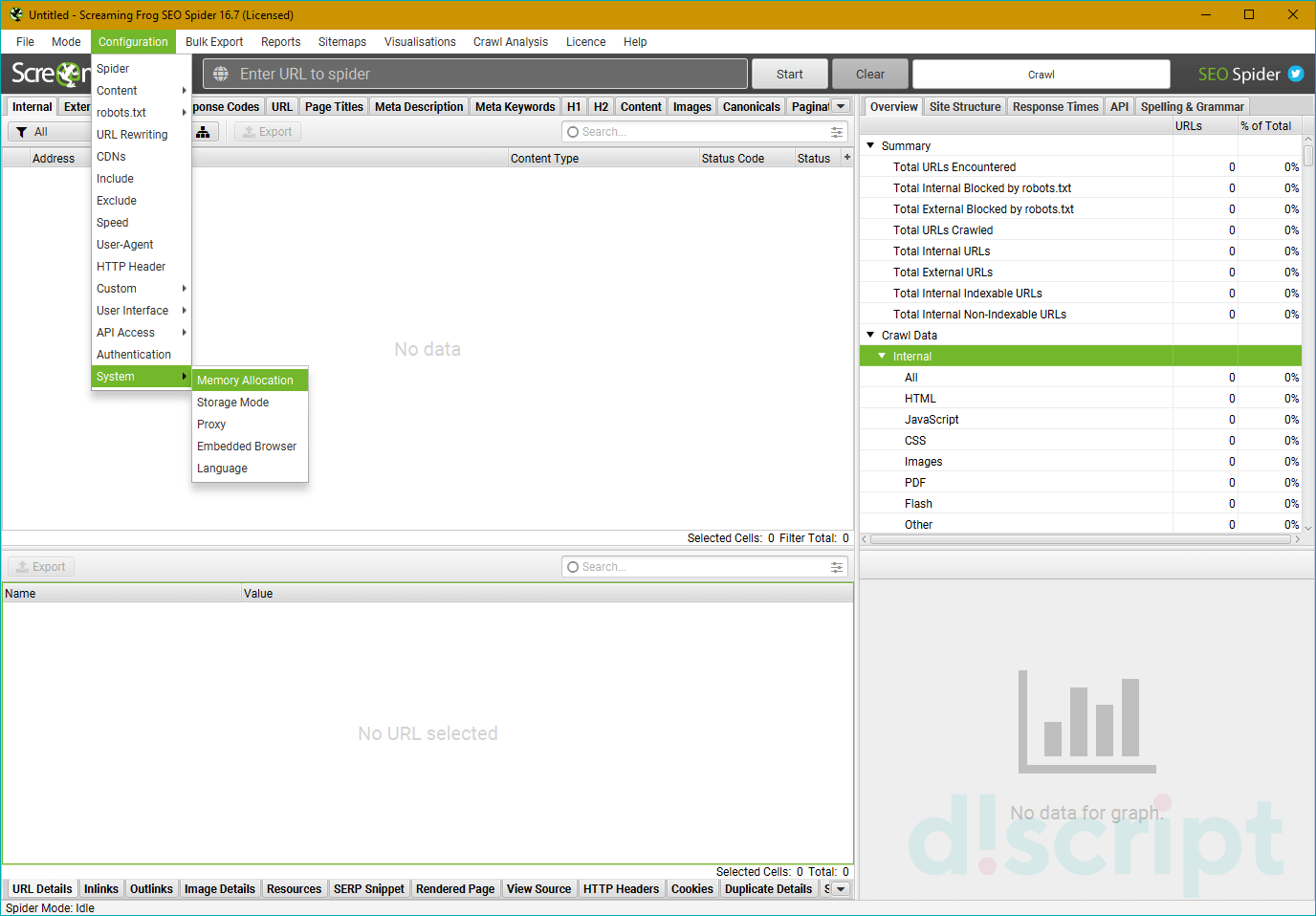
Позволяет задать настройки самой программе. Насчитывает 5 пунктов:
- Memory — указание лимитов оперативной памяти для парсинга. Стандартно стоит 2ГБ.
- Storage — выбирает режим сохранения информации. Ее можно хранить либо в оперативной памяти, либо в указанной пользователем папки.
- Proxy — при использовании позволяет указать данные подключенного прокси-сервера для парсинга.
- Embedded Browser — включает или выключает встроенный браузер приложения.
- Language — выбор языка. Русский не поддерживается.
Bulk Export
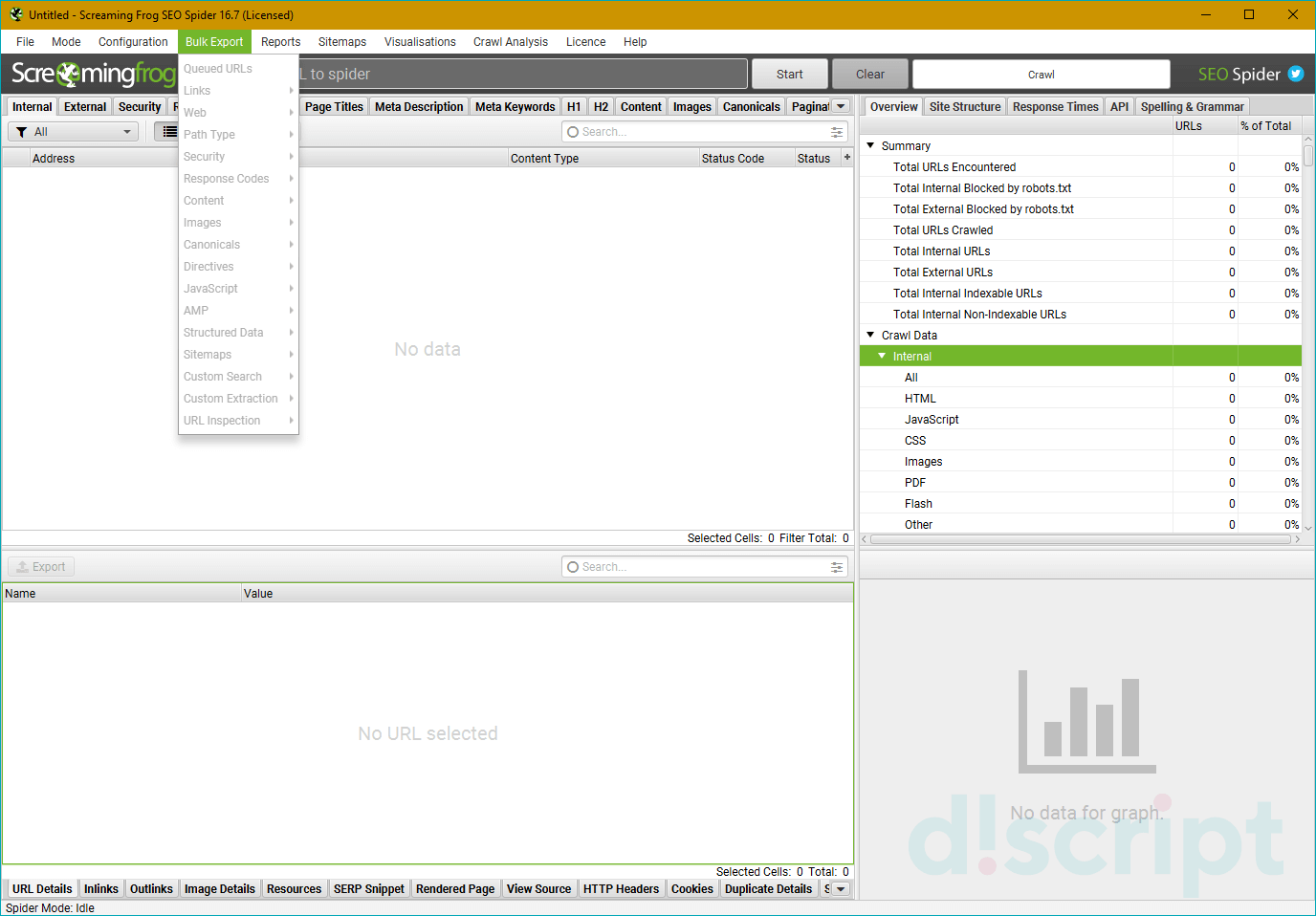
Здесь можно настроить массовый экспорт данных из отчетов. В целом, этот раздел можно использовать, чтобы вытягивать нужную информацию и затем составить ТЗ для доработок сайта.
Доступные подпункты меню экспорта:
- Queued URLs — все ссылки, которые были обнаружены и находятся в очереди на сканирование.
- Пункт Links
- All Inlinks — все входящие ссылки на URL-адреса, зафиксированные поисковым роботом во время парсинга.
- All Outlinks — все исходящие ссылки.
- All Anchor Text — экспорт анкоров со всех ссылок
- External Links — все внешние ссылки
- Пункт Web
- Screenshots — все сделанные скриншоты.
- All Page Source — статистический или визуализированный (rendered) HTML код просканированных страниц.
- All HTTP Headers
- All Cookies
- Path Type — позволяет экспортировать ссылки определенного типа со страницами, к которым они привязаны. Можно указать абсолютные, относительные, корневые и путевые (path-relative) ссылки.
- Security — страницы сайта с потенциально опасным контентом. Например, таким образом можно организовать экспорт ссылок, ведущие на страницы сайта с небезопасными линками.
- Response Codes — все страницы в зависимости от нужного кода ответа. Например, так можно выгрузить URL, ведущие на страницы с ошибкой 404.
- Content — весь контент. Может пригодиться, если нужно организовать экспорт дубликатов и составления последующего ТЗ на их удаление.
- All Images — выгрузка картинок без атрибута alt, слишком тяжелых изображений.
- Canonicals — все страницы-первоисточники.
- Directives — все директивы.
- AMP — все линки на AMP-контент.
- Structured Data — все ссылки из фильтра структурированных данных.
- Sitemaps — все страницы в карте сайта, неиндексируемые страницы в карте сайта и т.п.
- Custom Search — выгрузка всех элементов из пользовательского поиска.
- Custom Extraction — все элементы, заранее настроенные по фильтру пользовательского извлечения.
Reports
Вкладка, отвечающая за отчеты. Доступные подпункты меню:
- Crawl Overview — содержит всю сводку сканирования, включая обнаруженные URL-адреса, заблокированные файлом robots.txt, количество просканированных ссылок, типы контента, коды ответов и т.д.
- Redirects — описывает найденные перенаправления и URL-адреса, через которые удалось найти редиректы. Также здесь отображаются канонические цепочки перенаправлений и канонические символы, указывается количество переходов и цикличность (если она присутствует).
- Canonicals — в этом разделе показываются ошибки и проблемы, найденные с каноническими цепочками или элементами. В ответе канонических цепочек отображаются все URL, имеющие больше 2 канонических линков.
- Pagination — отображает ошибки и проблемы, связанные с атрибутами rel=next/prev, которые применяются для обозначения содержимого, разбитого на страницы.
- Hreflang — сообщает о возможных проблемах с атрибутами hreflang, например: некорректных ответах серверов, страниц без гиперссылок, разных кодах языка на 1 веб-странице и т.п.
- Insecure Content — содержит HTTPS URL-адреса, на которых были обнаружены небезопасные элементы. Например, внутренние ссылки без SSL-сертификата.
- SERP summary — позволяет быстро выгрузить URL-адреса, title и description страниц. Их длина будет указываться в символах, а ширина в пикселях.
- Orphan Pages — отображает список потерянных страниц, собранных при помощи Google Analytics API и Search Console, а также XML Sitemap, которые не были сопоставлены с URL, обнаруженными во время сканирования.
- Structured Data — показывает отчет об обнаруженных ошибках валидации микроразметки веб-страниц.
- PageSpeed — содержит отчет о скорости загрузки каждой страницы. Работает, только если была подключена интеграция PageSpeed Insights.
- HTTP Headers — содержит отчет по заголовкам HTTP, обнаруженных во время сканирования. Показывает каждый уникальный заголовок и количество URL, ответивших этим заголовком.
- Cookies — содержит отчет о файлах cookie, обнаруженных во время сканирования, с указанием имени, домена, срока действия, безопасности и значения HttpOnly.
Sitemaps
Через этот пункт меню можно создавать свои карты сайта в формате XML. На выбор предлагается 2 пункта:
- XML Sitemap — генерация XML-карты сайта
- Images Sitemap — генерация XML-карты сайта для определенного изображения.
После выбора нужного варианта откроется всплывающее окно, в котором можно будет задать нужные параметры — например, создание карты для закрытых от индексации страниц, URL, разбитых на пагинацию и т.п.
Страница имеет 6 вкладок.
Pages — отвечает за тип страниц, которые будут включены в карту сайта.
- Noindex Pages — закрытые от индексации страницы.
- Canonicalised — каноникализированные страницы, говоря простым языком с атрибутом rel=canonical.
- Paginated URLs — страницы пагинации.
- PDFs — PDF-файлы.
- No response — не отвечающие страницы.
- Blocked by robots.txt — страницы, закрытые от индексации файлом robots.txt.
- 2xx — страницы с кодом ответа сервера 2хх (работающие страницы).
- 3xx — страницы с редиректами.
- 4xx — битые ссылки.
- 5xx — страницы с проблемами сервера при загрузке.
Last Modified — необязательная опция, позволяет выставить дату последнего обновления карты. Можно установить использование тега lastmod, либо применять ответ сервера при создании карты. Также возможно ручное указание даты.
Priority — используется для выставления приоритета ссылки в зависимости от глубины страницы.
Change Frequency — используется для выставления вероятной частоты обновления веб-страниц с помощью тега changefreq. Рассчитать тег можно либо по последнему измененному заголовку, либо по глубине страницы.
Images — позволяет добавить картинки в карту сайта, включая закрытые от индексации картинки или изображения с конкретным числом входящих ссылок.
Hreflang — отвечает за использование или не использование атрибута hreflang в карте сайта.
Visualisations
С помощью этого пункта меню можно получить визуализированную структуру сайта, которая будет отображаться в программе.
Пользователю на выбор предоставляется несколько вариантов визуализации, которые отображаются во встроенном браузере — это повышает эффективность работы с ними. Например, их можно масштабировать прямо в Screaming Frog.
Доступные режимы:
- Crawl Tree Graph — визуализирует структуру сайта на основании сканирования в виде дерева каталогов.
- Directory Tree Graph — показывает все каталоги, найденные после сканирования. В отличие от первого режима, показывает даже папки, закрытые от индексации
- Force Directed Crawl-Diagram — похожий вариант на 2 других, только оформленный в виде кружков.
- Force Directed Tree-Diagram — похожий, но более масштабный способ визуализации.
- Inlink Anchor Text Word Cloud — визуализирует анкоры внутренних ссылок. Каждая страница отображается по отдельности. Помогает в анализе анкоров.
- Body Text Word Cloud — визуализирует плотность слов на веб-странице. Помогает понять, какие слова встречаются чаще других и нет ли переспама ими на странице.
Crawl Analysis
Помогает проанализировать и включить в отчет данные, которые не попадают в основную статистику в ходе сканирования. Это могут быть параметры Link Score, Orphan URLs (потерянные URL) и , и т.п.
Дополнительное сканирование запускается после основного парсинга. Во вкладке Configure можно настроить, какие данные будут добавляться в отчет.
Возможные опции:
- Link Score — присваивает оценки всем внутренним линкам веб-сайта.
- Pagination — показывает неправильно настроенные пагинации и страницы, которые были найдены только благодаря атрибуту rel next/prev.
- Hreflang — отображает URL с атрибутом hreflang без гиперссылок.
- AMP — показывает страницы без тегов HTML amp.
- Sitemaps — вносит в отчет неидексируемые страницы, найденные в карте сайта, дубли URL в нескольких sitemap, потерянные страницы.
- Analytics — потерянные страницы, найденные в аналитике.
- Search Console — потерянные страницы, найденные в консоли веб-мастера.
Licence
Раздел, в котором можно купить лицензию и ввести лицензионный ключ.
Help
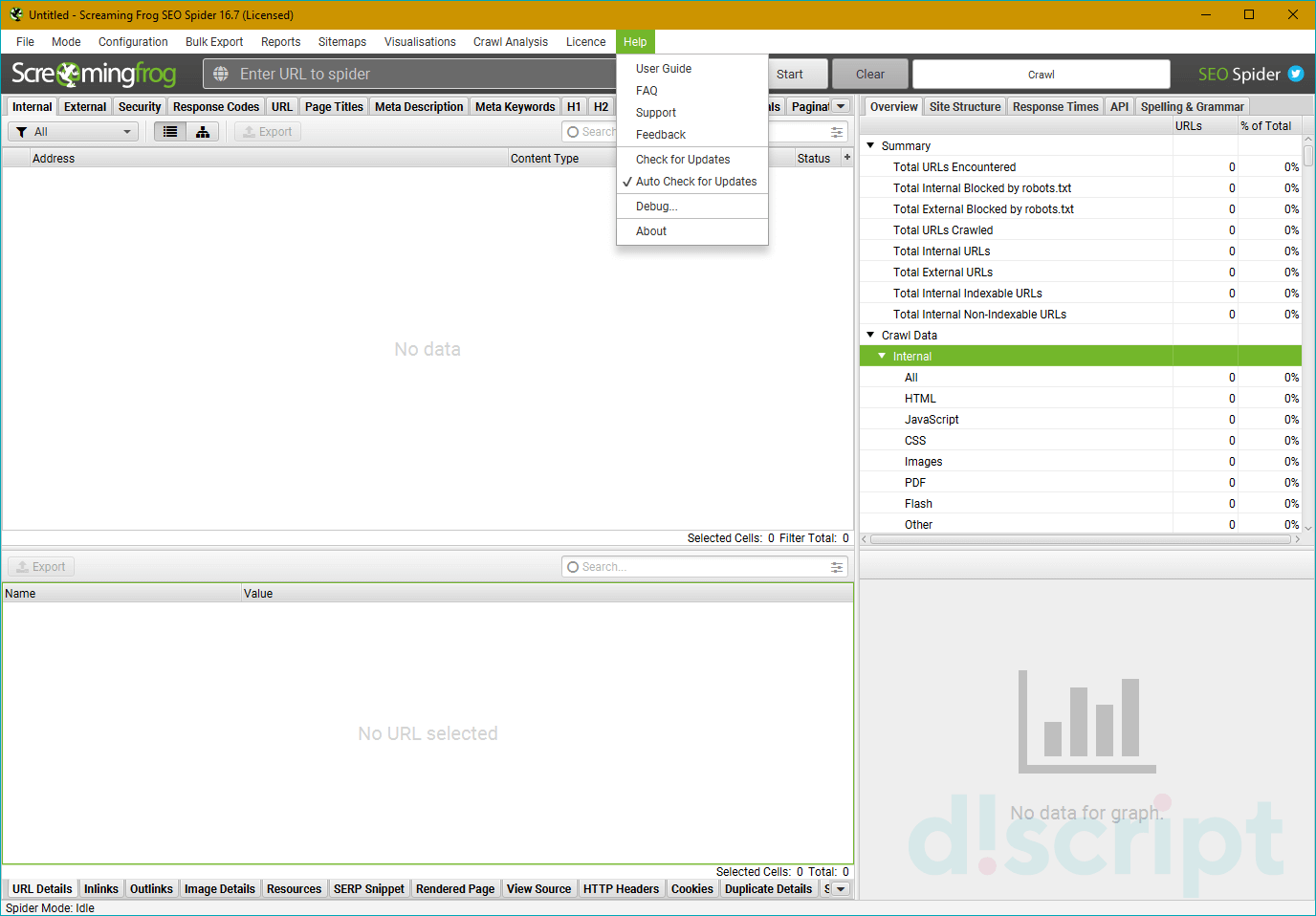
Пункт меню, в котором собрана информация, полезная пользователю.
Доступные подпункты:
- User Guide — супер-подробное руководство по работе с программой.
- FAQ — часто задаваемые вопросы.
- Support — техническая поддержка.
- Feedback — предложения по работе или новым функциям.
- Check for Updates — ручная проверка на наличие обновлений.
- Auto Check for Updates — автоматическая проверка на наличие обновлений.
- Debug — сообщить о каком-либо баге разработчику.
- About — краткая информация о программе.



