Содержание:
- Зачем нужна сохраненная копия страницы и как её посмотреть
- Как посмотреть сохраненную копию в Google
- Как посмотреть сохраненную копию веб-страницы в Яндекс
- Почему сохраненной страницы может не быть
- Специализированные веб-архивы
- Выводы
Чтобы пользователь нашел документ в поисковой выдаче, недостаточно добавления его на сервер. Контент должен быть проиндексирован (добавлен поисковыми роботами в индекс) поисковыми системами Яндекс и Google. Поэтому, наличие сохраненной копии — показатель что поисковый бот был на странице. Рассмотрим, что можно посмотреть и какие ошибки обнаружить с помощью сохраненной копии веб-страницы.
Роботы Яндекса и Google добавляют копии найденных веб-страниц в специальное место в облаке — кеш. При этом новая копия страницы перезаписывает старую. Поэтому в кеше отображаются свежие версии веб-страниц.
Сохраненная копия — это версия веб-страницы, которая сохранена в кэше поисковой системы. Условно это бесплатная резервная копия от поисковых систем.
На самом деле веб-страницы сохраняют:
- Поисковые системы. В них находится находится последняя проиндексированная версия страницы. Такие «снимки» используют SEO-специалисты, чтобы увидеть какие данные обнаружил на странице поисковый бот;
- Специализированные сервисы. Занимаются сохранением содержимого веб-страницы. Основная задача таких сервисов сохранить страницы в конкретный момент времени. С помощью них вы можете узнать как выглядел сайт или страница несколько лет назад.
Зачем нужна сохраненная копия страницы и как её посмотреть
На сайтах регулярно происходит добавление нового и редактирование существующего контента. Периодически изменяется его дизайн, добавляются и/или удаляются графические элементы. Это трудоемкая работа в процессе, которой могут возникнуть ошибки: потеряться контент, «съехать дизайн», удалиться блок или перестать индексироваться часть материала. Выявить, как выглядела страницы до определенного момента, поможет сохраненная копия.
Пример из практики:
Есть у нас технически сложный проект, который при заполнении объема памяти перестает, корректно работать. Если по простому, то вместо работающего сайта, мы видим ошибку базы данных.
Время от времени сайт отваливается по ночам, а утром разработчики все исправляют. И тут важный момент, сохраненные копии, позволяют понять успели ли поисковые системы проиндексировать сломанный сайт или нет. А также позволяют выявить, какие именно страницы успел переобойти бот.
Как посмотреть сохраненную копию в Google
Рассмотрим на примере страницы https://discript.ru/prodvizhenie-sajtov/kolomna/. Перед url адресом пропишите оператор «site:». В сниппете (блок информации о странице веб-сайта) результата, нажмите на иконку в виде треугольника, выберите соответствующий пункт.
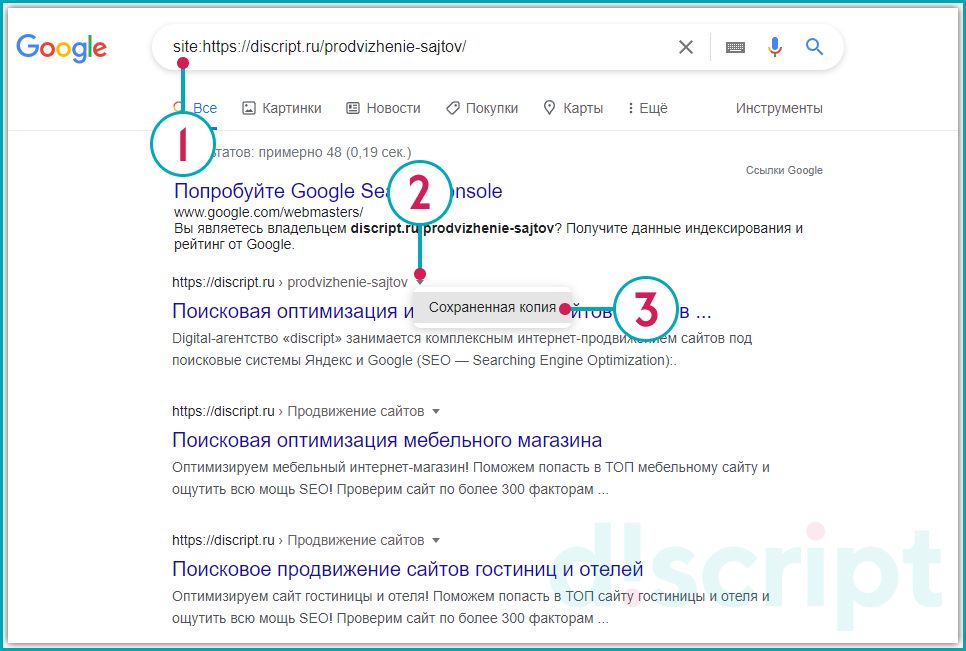
Откроется сохраненная копия веб-страницы. Google выведет окно с сообщением, что открылся «снимок» страницы.
Разберем представленную информацию:
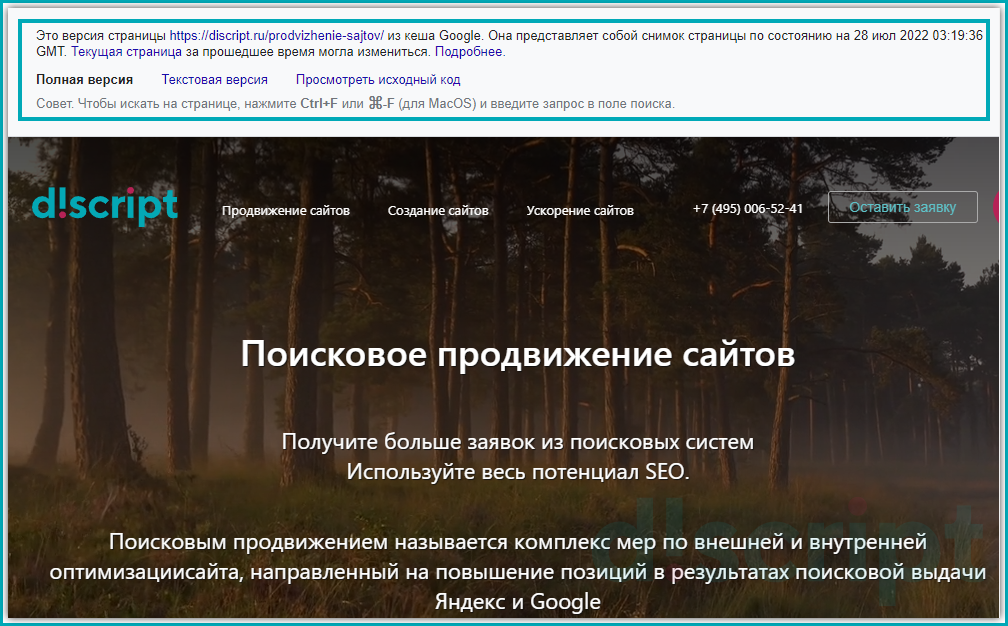
- Дату фиксации. В данном параметре указано, когда был сделан слепок страницы. Поэтому сопоставив указанную дату с датой внесения правок, можно предположить успел ли поисковый бот обойти страницу или еще нет (Важно! данный метод не гарантирует 100% верную информацию, т.к. данные хранятся в кеше и могут отличаться в зависимости от вашего место нахождения) ;
- Полная версия. Отображается версия страница, как должен был ее увидеть пользователь.
- Текстовая версия. Позволяет просмотреть контент веб-страницы без применения стилей. Такой формат позволяет увидеть скрытые от пользователя элементы, но доступные для поисковых роботов Яндекса и Google;
- Исходный код. Выводит исходный код HTML-страницы. Это требуется для изучения тега Title и мета тегов, таких как Description. Данное представление позволяет изучить, как сверстана веб-страница, и нет ли на ней критических ошибок.
Как посмотреть сохраненную копию веб-страницы в Яндекс
Рассмотрим на примере страницы https://discript.ru/site-development/. В строку поиска обязательно пропишите оператор «url:» перед url-адресом. нажмите на значок в виде трех горизонтальных точек, выберите «Сохраненная копия».
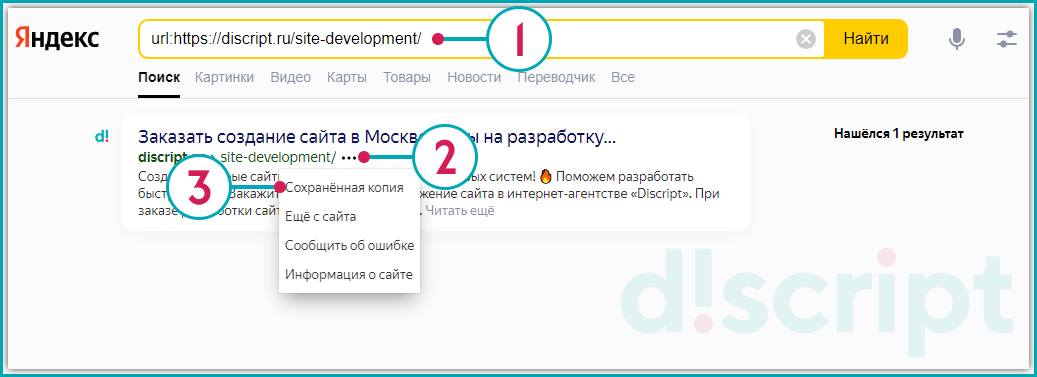
Далее Яндекс предоставит следующие данные:
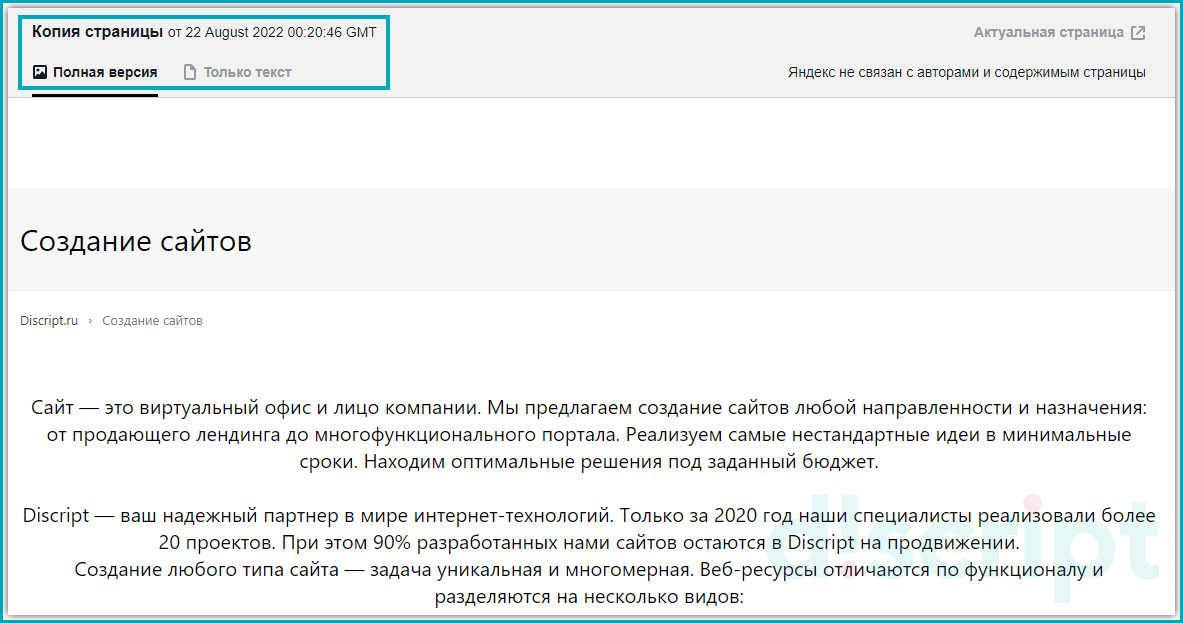
- Дата индексации. Данное значение информирует в какой момент выполнен слепок страницы.
- Полная версия страницы. Отображение страницы со всеми стилями.
- Текстовая версия страницы. Текстовая версия, аналогично позволяет изучить страницу без стилей и получить всю скрытую информацию. Часто именно при проверке текстовой копии обнаруживаются сквозные блоки текста на страницах. Т.к. при использовании стилей они скрыты.
Почему сохраненной страницы может не быть
Это происходит в результате:
- Сбой работы поисковых систем. Разработчики Яндекса даже говорят, что нет стопроцентной гарантии, что страница сохранится. Конкретная причина не указывается.
- HTML-код содержит мета тег мета-тег «robots» со значением «noarchive», что означает запрет на кэширование (локальное сохранение данных для получения быстрого доступа к странице при следующих запросах).
Что предпринять если в ПС нет сохраненной копии, а посмотреть содержимое нужно? Попробуйте изучить специализированные площадки и расширения.
Рассмотренными выше способами можно посмотреть:
- Мобильную версию веб-сайта. Пропишите url мобильной версии в Яндексе или Google. Из выдачи перейдите на нее далее, как в примере рассмотренном выше.
- Адаптивную версию. Перейдя в сохраненную копию (так же как в примере выше). Открываем инструменты разработчика. Клавиша F12 в обозревателе. Или нажать ПКМ на пустом месте страницы, выбрать «Посмотреть код». Переходим в раздел мобильное отображение и перезагружаем веб-страницу.
Специализированные веб-архивы
Выше мы обсуждали, что существуют сервисы, задачи которых сохранять в истории страницы сайтов. Сейчас рассмотрим их подробнее и расскажем, как с ними работать.
И начнем с самого популярного и известно.
Wayback Machine
Сервис Wayback Machine — бесплатным онлайн-архивом, задача которого является сохранить и архивировать информацию размещенную в открытых интернет‑ресурсах. Wayback Machine является частью некоммерческого проекта Интернет Архива. На его серверах хранятся копии веб-сайтов, книг, аудио, фото, видео.
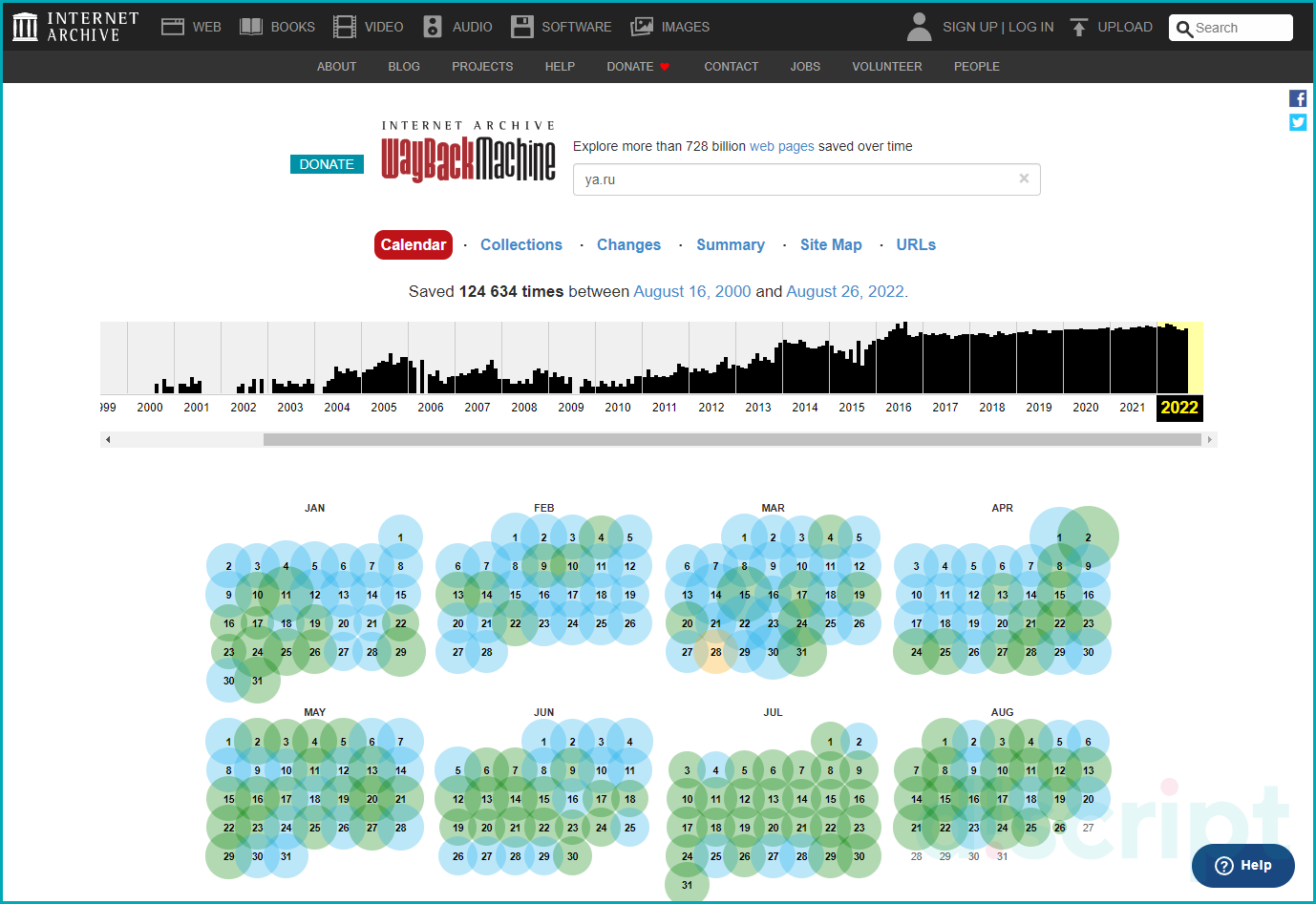
Чтобы открыть копию страницы перейдите на https://archive.org/, далее откроется поисковая форма, куда пропишите URL страницы. Нажмите кнопку «GO».

Сервис отобразит имеющиеся в архиве снимки.
Далее выберите в календаре нужную дату и откройте страницы. Результатом вывода будет открытие страницы, которую зафиксировали роботы за выбранную дату.
Кроме просмотра снимков страниц, сервис поможет:
- Проанализировать robots.txt. Сервис будет сканировать веб-сайты вне зависимости от настроек robots.txt;
- Узнать данные о домене. Актуально перед покупкой. Уточните какая информация размещалась на нем. Если вы купите «заспамленный» или домен под «санкциями» (например была размещена информация для взрослых) новый контент будет плохо ранжироваться. Если же ранее на нем размещалась информация, которая подходит по тематике и качеству для вашего будущего ресурса, тогда вы сможете использовать ее на этом же домене.
- Найти в архивных копиях пропавшую информацию.
- Если, например, на веб-сайте наблюдается спад трафика, откройте сохраненную версия сайта до момента уменьшения посещаемости. Проанализируйте, какие были сделаны изменения, чтобы разобраться в причине падения посещаемости.
Archive.Today
Archive.Today — бесплатный некоммерческий севрис сохраняющий веб-страницы в оналйн режиме. Особенность — сохраняет не только статические страницы, но и генерируемые Веб 2.0-проектами страницы. Например, карты Google.
Основное отличие от Wayback Machine, что Archive.Today сохраняет веб-страницы только по запросу пользователей. При этом сервер полностью сохраняет:
- HTML-страницы,
- CSS файлы,
- JS файлы,
- PDF,
- аудио файлы,
- пр.
Важно, помнить, что Archive.Today игнорирует файл robots.txt поэтому в нем можно сохранить страницы недоступные для Wayback Machine.
Обратите внимание, общий в Размер заархивированной страницы со всеми изображениями не должен превышать 50 МБ.
У Archive.Today есть собственное приложение для браузера Mozilla Firefox. Ссылка на ПО https://addons.mozilla.org/en-US/firefox/addon/archive-page/
Для начала работы с Archive.Today перейдите по адресу: https://archive.md/. Чтобы получить результат укажите в форму интересующий URL-адрес.
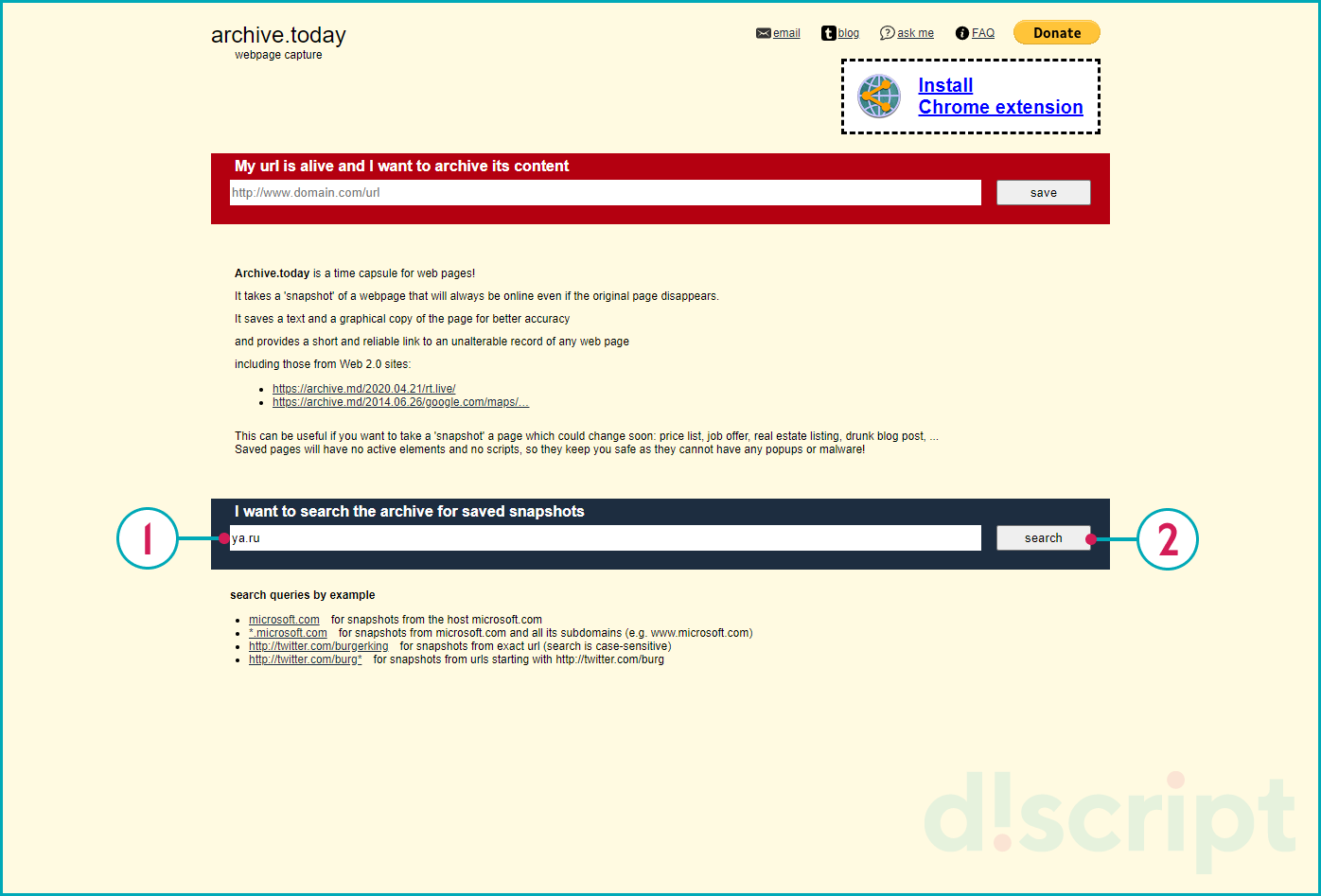
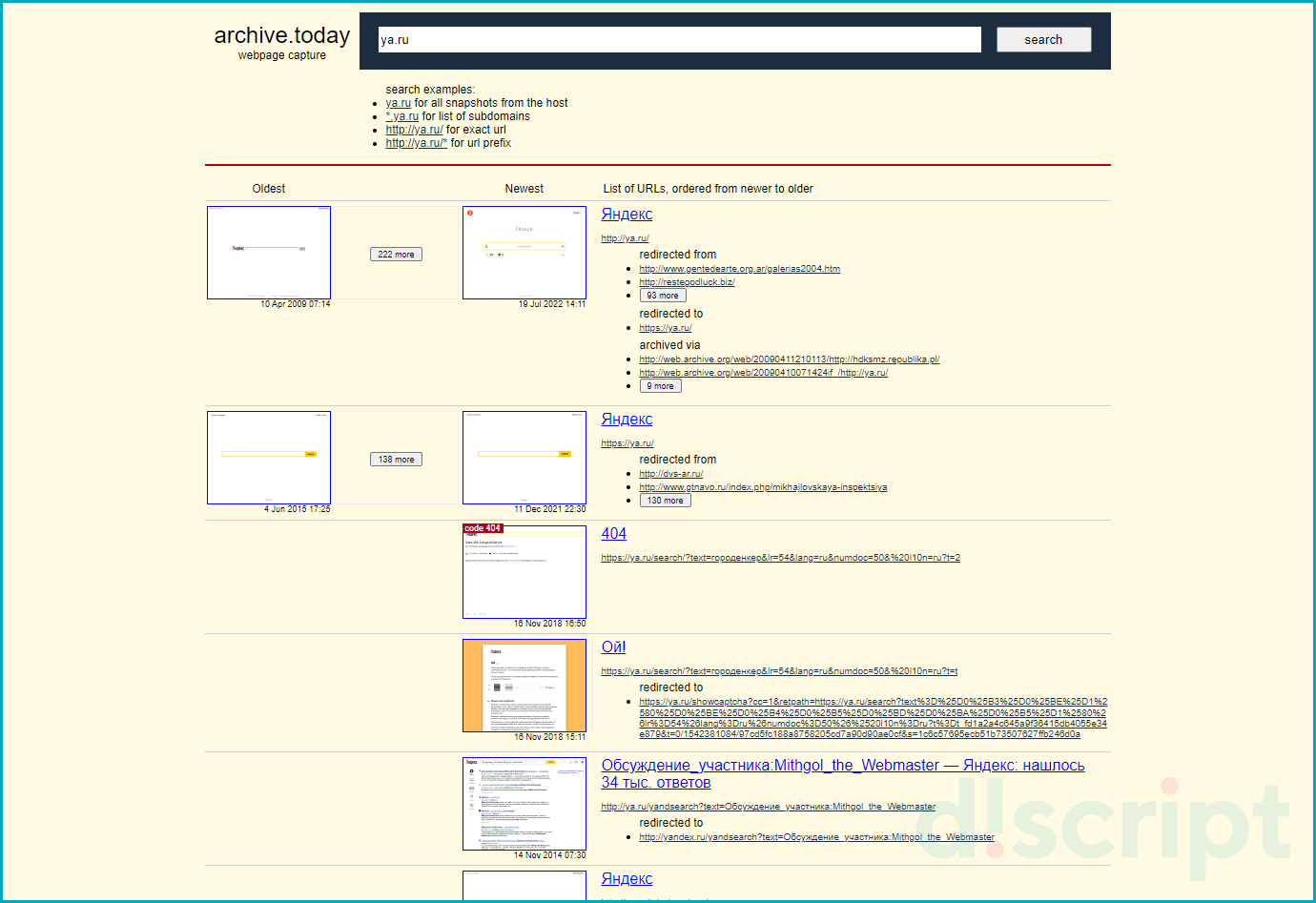
Откроется страница с сохраненными снимками и информацией о дате создания копии.
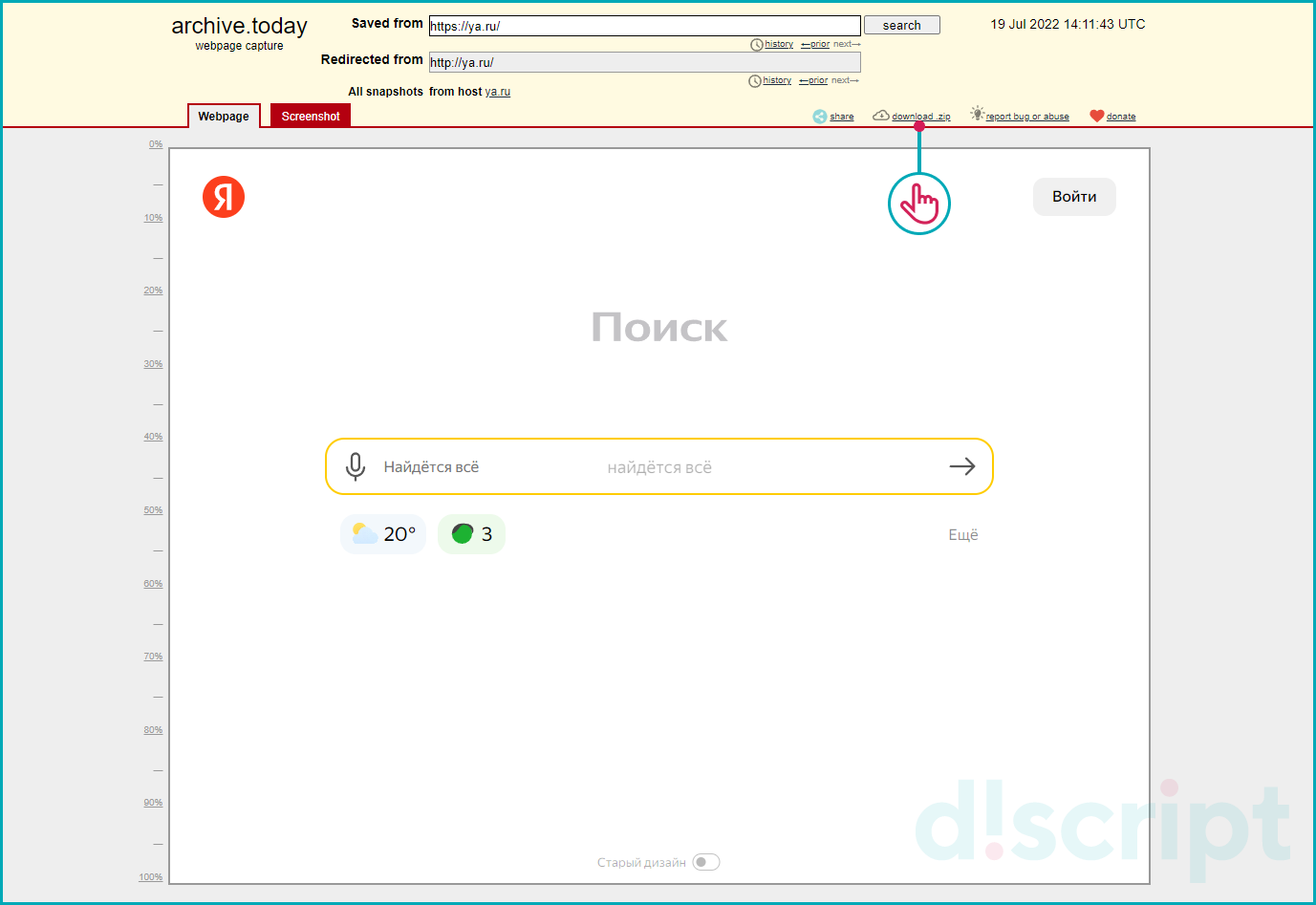
Вы можете скачать сохраненную копию виде архива. И восстановить версию страницы у себе на сервере.
Расширения для браузеров
Существуют, плагины для браузеров, позволяющие создавать и просматривать сохраненные версии страниц.
Например, расширение Web Cache Viewer позволяет:
- Загружать веб-страницу из локального кэша на компьютере;
- Автоматически находить страницу при помощи сервиса Wayback Machine.
Перейдя по ссылке, рассмотренной, выше, нажмите кнопку «Установить».
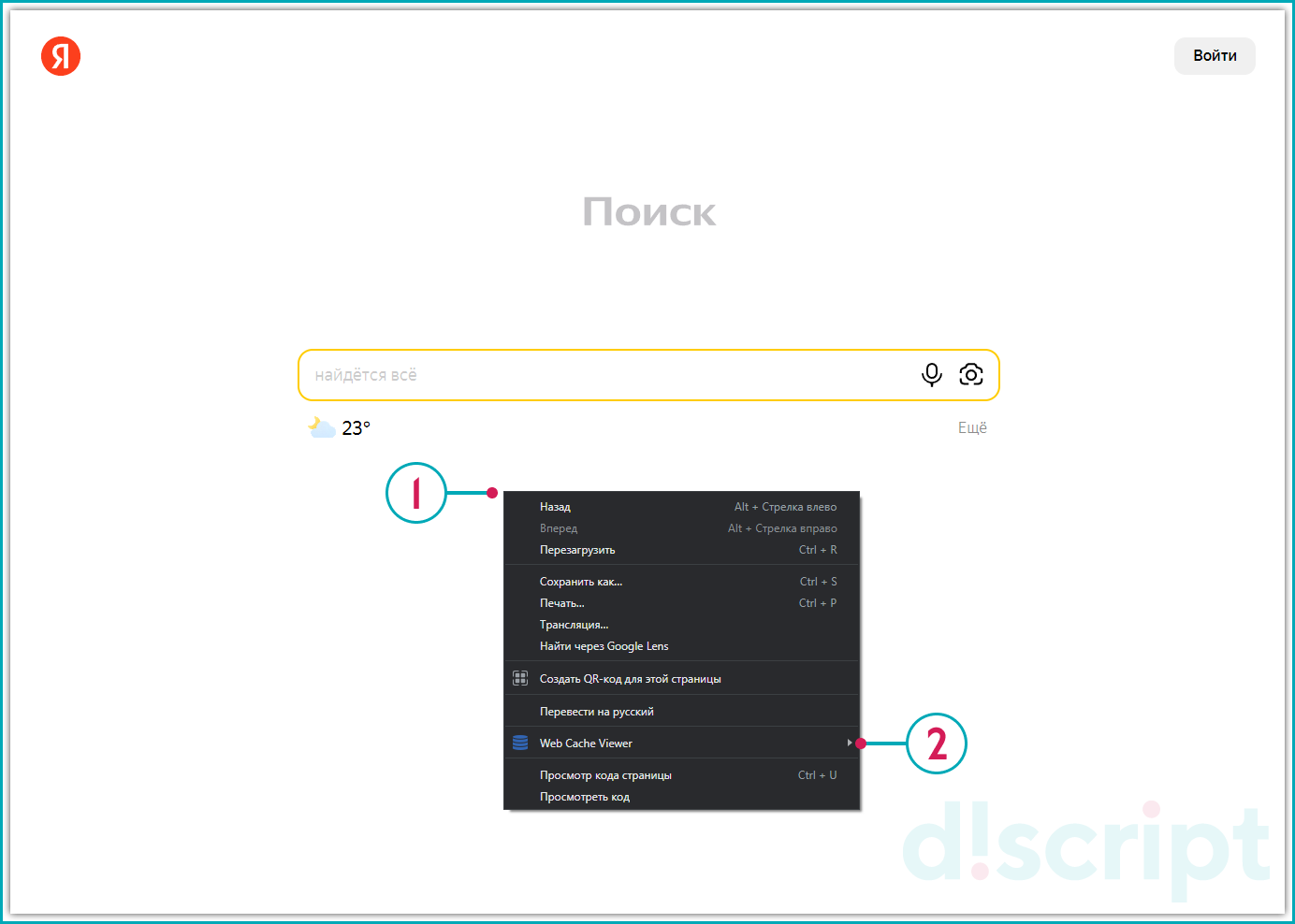
После инсталляции расширения в браузере, нажмите правой кнопкой мыши пустом месте страницы для просмотра версии из Google или Wayback Machine.
Для пользователей Firefox существует аналогичное дополнение со схожим функционалом Web Archives.
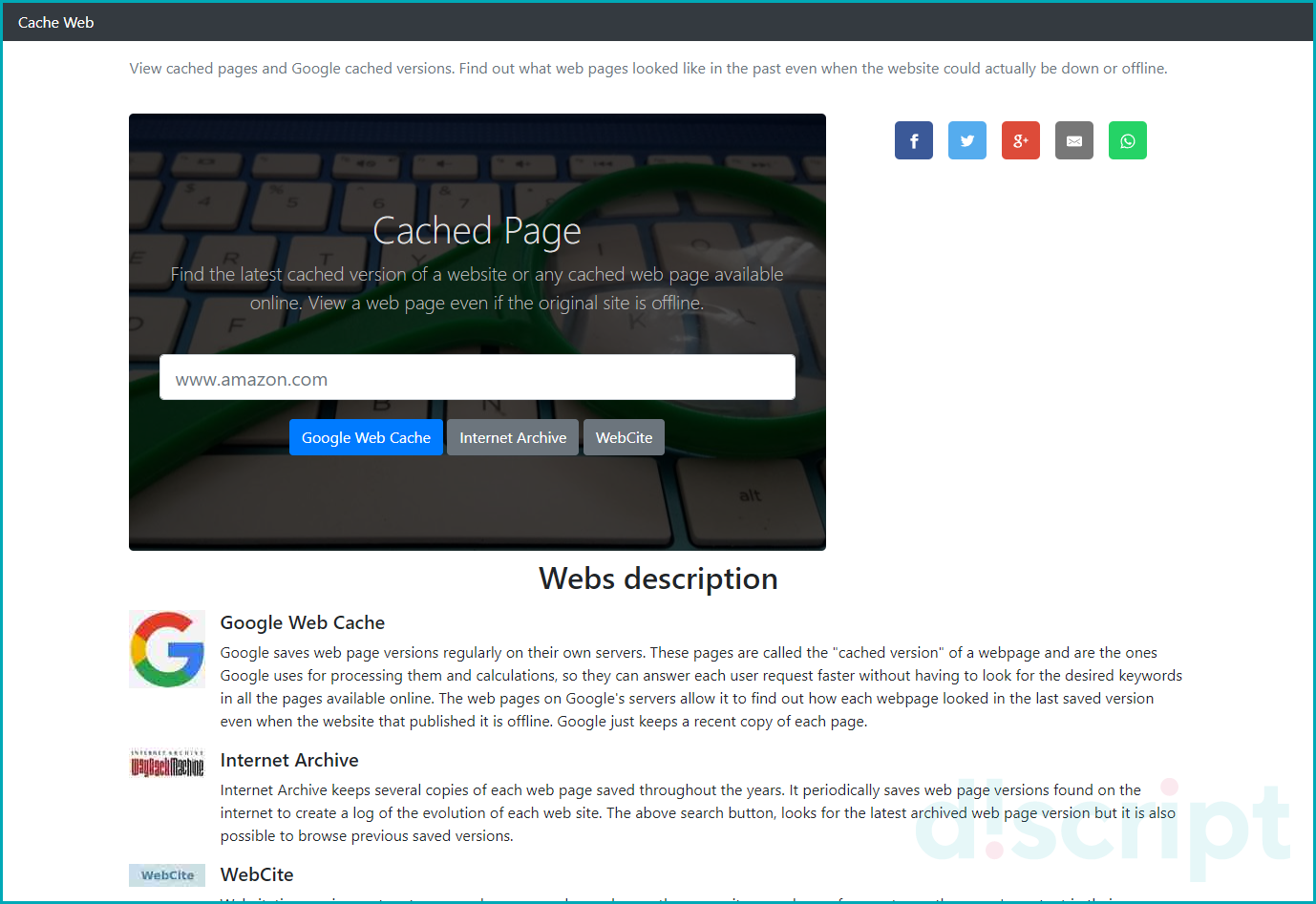
Cached Page
Веб-сайт Cached Page ищет копии веб-страниц в поиске Google, Интернет Архиве, WebSite. Используйте площадку, если описанные выше способы не помогли найти сохраненную копию веб-сайта.
Пропишите название сайта в специальную форму. Для поиска нажмите одну из трех кнопок. Сервис предложит произвести поиск веб-страницы в:
- Веб-кэш Google;
- Интернет Архив;
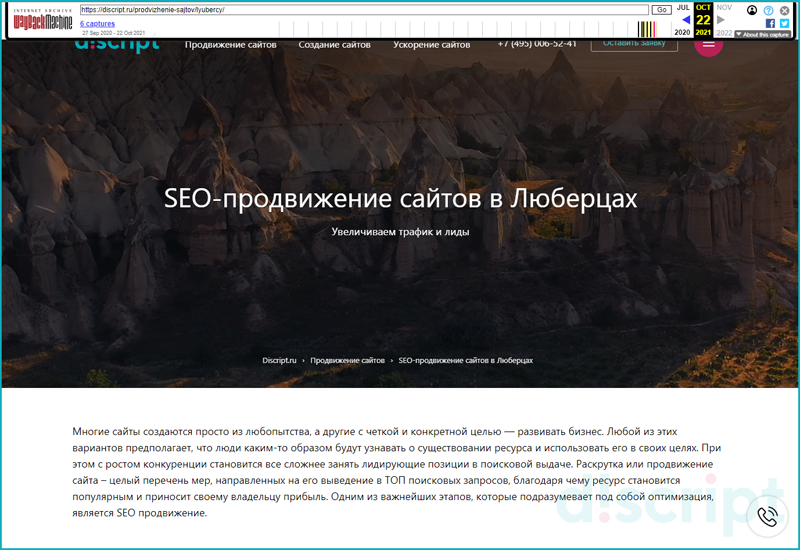
Например, прописав в форму адрес https://discript.ru/prodvizhenie-sajtov/lyubercy/, и нажав кнопку «Архив Интернета», произойдет переход на страницу сервиса Wayback Machine. Если страница сохранена в БД сервиса, она отобразится на странице.
Выводы
Работая с сохраненными копиями страниц, можно выявить достаточного много полезных нюансов.
Сохраненные копии позволяют:
- Узнать, поисковый бот успел ли обойти вашу страницу после внесенных правок.
- Как бот воспринимает информацию со страницы. Все ли учитывает или остались места, которые ПС не видят.
- Выявить, какие элементы пропали и когда.
- Выявить, какие страницы успел обойти поисковый бот, после того, как сайт перестал быть доступным.
- Создать копии страниц.
- Восстановить копию сайта, когда забыли оплатить домен.
Сохраненная копия веб-страницы поможет определить, какая версия документа проиндексирована поисковыми роботами и участвует в ранжировании. Поэтому наличие «снимка» страницы в Яндексе и Google говорит об успешной проведенной индексации.



