Дубли Title или Description — это всегда плохо. Рекомендуется для каждой страницы сайта использовать уникальные теги Title и мета-теги Description. Если же на разных страницах совпадают мета-теги, то при работах по поисковой оптимизации это может быть проблемой.
Новый функционал от Яндекса позволяет определить дубли Title или Description и их объем.
Найти данную информацию можно в меню раздела «Индексирование» и в сводке. Там же предлагается посмотреть примеры страниц с дублями, перейдя по соответствующей ссылке:
- Сколько страниц содержит одинаковые Title и сколько одинаковые Description
- Рекомендации как это исправить
Сервис позволяет увидеть конкретные страницы, на которых в заголовках или описаниях Вебмастер обнаружил дубли. Все полученные сведения можно экспортировать в таблицу для более наглядного представления. Кроме этого сервис позволяет находить страницы, которые перестали работать и выводят одинаковую ошибку, а также страницы, для которых теги уже обновили, но робот этого еще не видел.
Мы изучили работу сервиса и попробовали разобраться с ним подробнее!
Найти в вебмастере можно так:
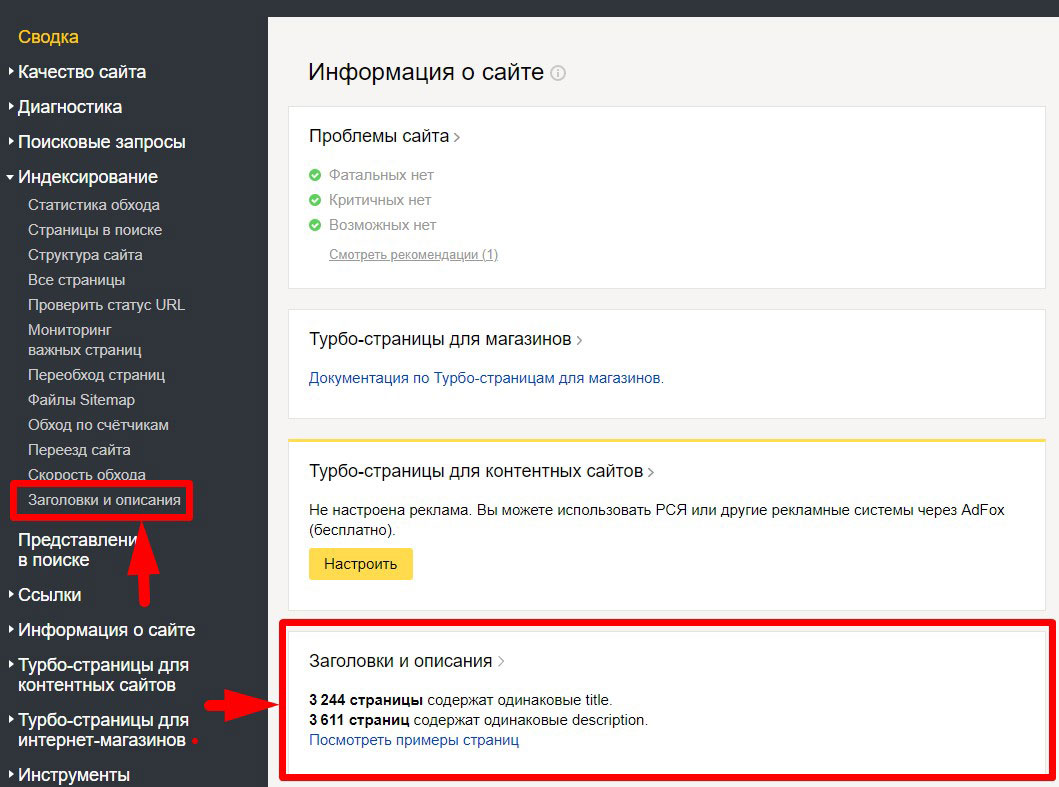
Общий вид при переходе по ссылке «Посмотреть примеры страниц»
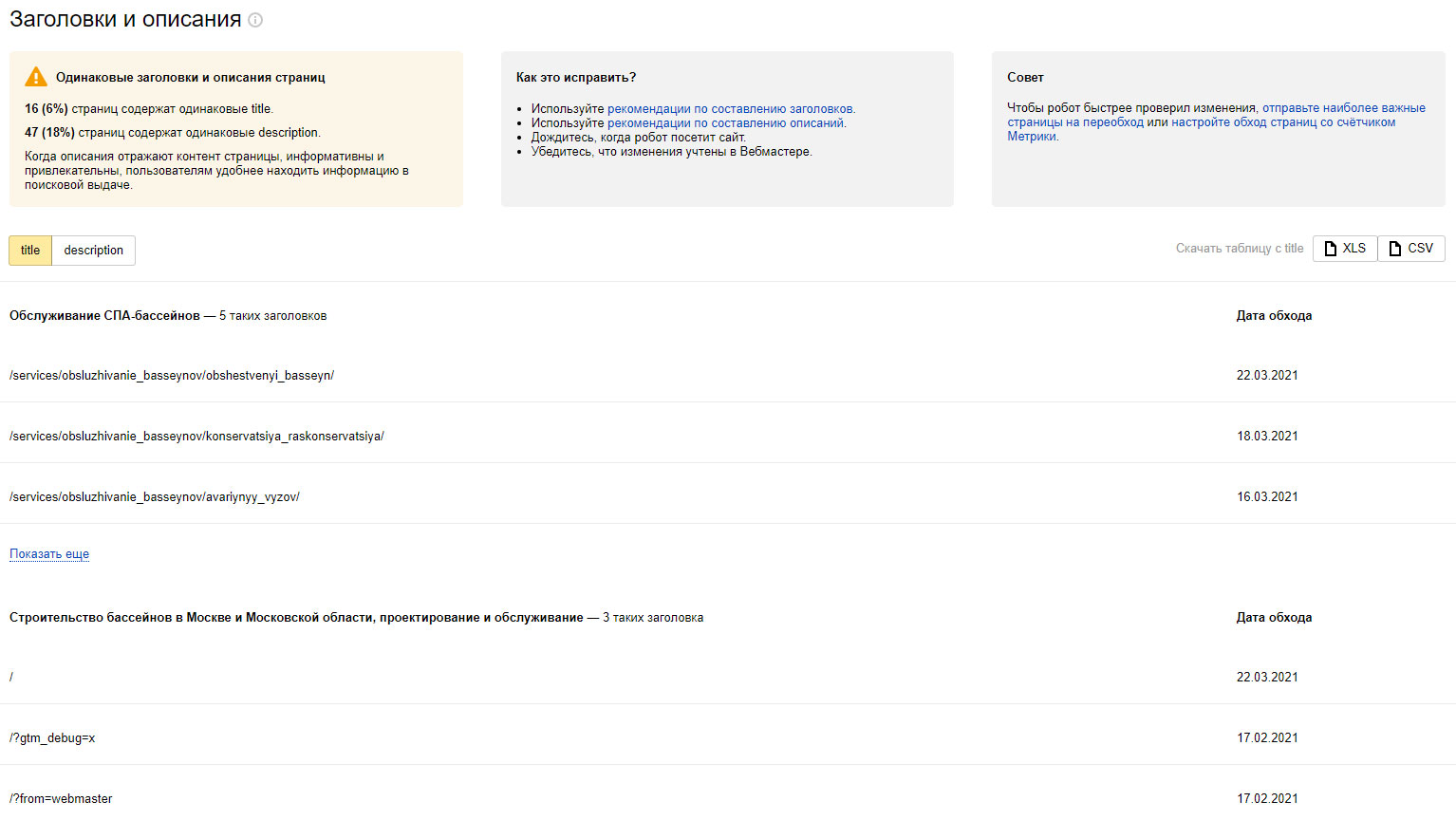
Есть возможность экспортировать результаты в XLS и CSV формате.
Особенности: в выгрузке может быть до 1000 групп, а в каждой группе до 50 примеров.

Пример экспортированной таблицы:

Сравним данные Яндекса с данными из других инструментов.
Проект 1
Данные из Вебмастера:

То что нашел Screaming Frog:
Title
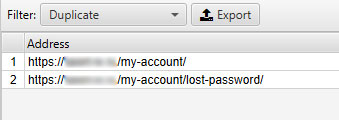
Description

В вебмастере нашли 46 страниц дублей Title и 7 страниц Description, но используя краулер, мы нашли только 2 страницы с одинаковыми Title и 13 страниц с дублями тегов Description. Как видим, в Яндексе значительно больше дублей Title и при ручной проверке выявлено, что данные актуальны. Из этого можем сделать вывод, что Яндекс предоставляет информацию о дублях, ссылок на которые может не быть на сайте.
И вторая особенность, что в сводку Яндекса не попали страницы, закрытые от индексирования с помощью canonical. Из данного наблюдения можем сделать вывод, что данные выводятся для страниц, находящихся в индексе.
Проект 2
Данные из Вебмастера:

То что нашел Screaming Frog:
Title

Description
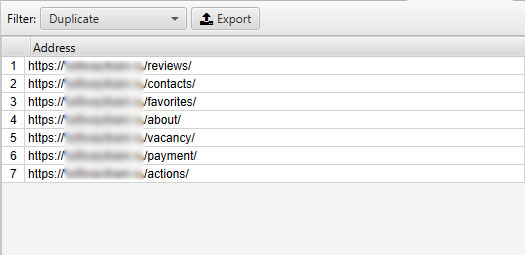
В вебмастере нашли 45 страниц дублей Title и 57 страниц Description. С помощью краулера мы не нашли дублей Title, а дублей мета-тега Description нашли у 7 страниц. В данном примере Яндекс аналогично знает немного больше.
Вместо выводов:
Какие страницы Яндекс добавляет в данный сервис?
Яндекс проверяет страницы, которые попадают в индекс, в том числе на которые нет прямых ссылок.
Как быстро обновляется информация?
Скорее всего, как и с другими рекомендациями вебмастера, задержка составит 2-4 дня.
Страницы, которые не попали в индекс, но просканированы, тоже будут выводится?
Таких страниц мы не обнаружили. Скорее всего в выдачу попадут только проиндексированные страницы.
В чем еще польза данного функционала?
Можно находить страницы, которые перестали работать и начали выводить одинаковую ошибку. И страницы, для которых теги уже обновили, но робот на страницы давно не заходил — в этом случае должны задублироваться теги с какой-то из страниц.
Почему в панели вебмастера больше дублей, чем в выгрузке?
Как было озвучено, при выгрузке есть ограничения до 1000 групп и на каждую группу до 50 примеров.
Другие статьи




Отправьте заявку и уже завтра мы начнем работы.
Спасибо за обращение!
В ближайшее время мы с вами свяжемся.